











 Peter Holmes
Peter Holmes 0
0  1157
1157 123
123
Jste věřící v myšlenku, že jakmile bude něco zveřejněno na internetu, bude publikováno navždy? No, dnes mýty rozptýlíme.
Pravda je, že v mnoha případech je možné vymýtit informace z internetu. Jistě, existuje záznam webových stránek, které byly smazány, pokud prohledáváte Wayback Machine, že? Jasně. Na Wayback Machine jsou záznamy o webových stránkách, které se vrací mnoho let - stránky, které nenajdete s vyhledáváním Google, protože webová stránka již neexistuje. Někdo to smazal, nebo se web vypnul.
Takže se to nedá obejít, že? Informace budou navždy vyryty do kamene internetu, budou tam vidět generace? No, ne přesně.
Pravda je, že ačkoliv může být obtížné nebo nemožné vymazat hlavní zpravodajské příběhy, které se rozšířily z jednoho zpravodajského webu nebo blogu na jiný, jako je virus, ve skutečnosti je docela snadné zcela vymazat webovou stránku nebo několik webových stránek ze všech záznamů. existence - odstranit tuto stránku jak pro vyhledávače, tak i pro Wayback Machine Nový Wayback Machine vám umožní vizuálně cestovat zpět v internetovém čase Nový Wayback Machine vám umožňuje vizuálně cestovat zpět v internetovém čase Zdá se, že od spuštění Wayback Machine v V roce 2001 se majitelé stránek rozhodli vyhodit back-end založený na Alexě a přepracovat jej pomocí vlastního otevřeného zdrojového kódu. Po provedení zkoušek s…. Je tu samozřejmě úlovek, ale dostaneme se k tomu.
3 způsoby, jak odebrat blogové stránky ze sítě
První metoda je ta, kterou většina majitelů webových stránek používá, protože nevědí nic lepšího - jednoduše smazat webové stránky. K tomu může dojít, protože jste si uvědomili, že na svém webu máte duplicitní obsah, nebo protože máte stránku, kterou nechcete ve výsledcích vyhledávání zobrazovat..
Jednoduše smažte stránku
Problém s úplným odstraněním stránek z vašeho webu je, že protože jste již stránku založili na síti, pravděpodobně budou existovat odkazy z vašeho vlastního webu i externí odkazy z jiných webů na tuto konkrétní stránku. Když ji smažete, Google tuto vaši stránku okamžitě rozpozná jako chybějící stránku.
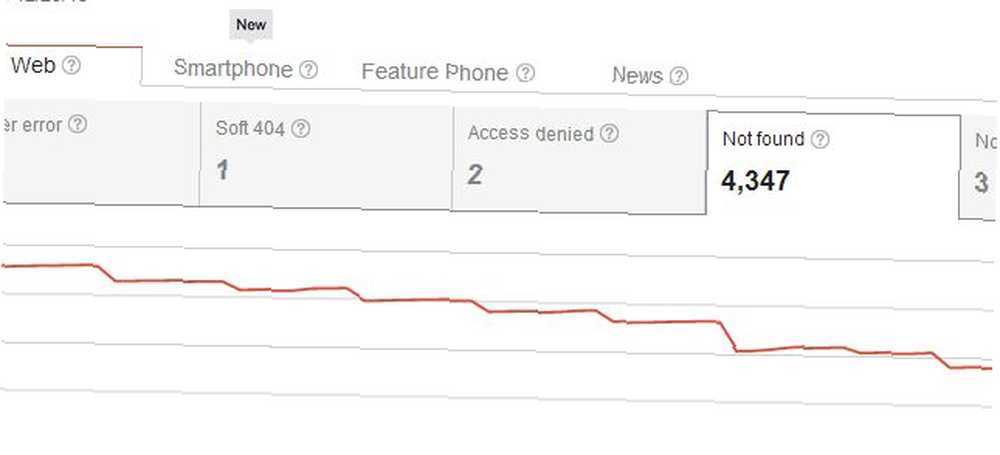
Při mazání stránky jste tedy nejen vytvořili problém “Nenalezeno” chyby procházení pro sebe, ale také jste vytvořili problém pro kohokoli, kdo kdy odkazoval na tuto stránku. Uživatelé, kteří se na váš web dostanou z jednoho z těchto externích odkazů, obvykle uvidí vaši stránku 404, což není hlavní problém, pokud použijete něco jako vlastní kód 404 společnosti Google, abyste uživatelům poskytli užitečné návrhy nebo alternativy. Ale domníváte se, že by mohly existovat elegantnější způsoby mazání stránek z výsledků vyhledávání, aniž by se všechny tyto 404 začaly stahovat za existující příchozí odkazy,?
No, jsou.
Odebrání stránky z výsledků vyhledávání Google
Nejprve byste si měli uvědomit, že pokud webová stránka, kterou chcete odstranit z výsledků vyhledávání Google, není stránkou vašeho vlastního webu, pak máte štěstí, pokud neexistují právní důvody nebo pokud web nezveřejnil vaše osobní údaje. informace online bez vašeho svolení. Pokud je to váš případ, použijte k odstranění žádosti z výsledků vyhledávání nástroj Google pro odstraňování problémů. Máte-li platný případ, může se vám po odstranění stránky stát nějaký úspěch - samozřejmě můžete mít ještě větší úspěch jen kontaktování vlastníka webu Jak odstranit nepravdivé osobní údaje na internetu Jak odstranit nepravdivé osobní údaje na internetu, jak jsem popisuje, jak postupovat v roce 2009.
Pokud je tedy stránka, kterou chcete z výsledků vyhledávání odebrat, na vašem vlastním webu, máte štěstí. Vše, co musíte udělat, je vytvořit robots.txt soubor a ujistěte se, že jste ve výsledcích vyhledávání zakázali konkrétní stránku, kterou nechcete, nebo celý adresář s obsahem, který nechcete indexovat. Vypadá to, že blokování jedné stránky vypadá.
User-agent: * Disallow: /my-deleted-article-that-i-want-removed.html
Následujícím způsobem můžete blokovat robotům procházení celých adresářů vašeho webu.
User-agent: * Disallow: / content-about-personal-stuff /
Google má vynikající stránku podpory, která vám pomůže vytvořit soubor robots.txt, pokud jste jej ještě nikdy nevytvořili. Funguje to velmi dobře, jak jsem nedávno vysvětlil v článku o strukturování syndikačních obchodů Jak vyjednat nabídky syndikace a chránit hodnocení vyhledávání Jak vyjednat nabídky syndikace a chránit hodnocení vyhledávání Syndikace je v dnešní době zlost. Najednou ale zjistíte, že partner pro syndikaci je ve výsledcích vyhledávání uveden výše než vy ve příběhu, který jste původně napsali! Chraňte své hodnocení ve vyhledávání. aby vás neubližovali (požádali partnery syndikace, aby zakázali indexování svých stránek, kde jste syndikováni). Jakmile můj vlastní partner pro syndikaci souhlasil s tím, stránky, které byly duplikovaným obsahem z mého blogu, úplně zmizely z výpisů vyhledávání.
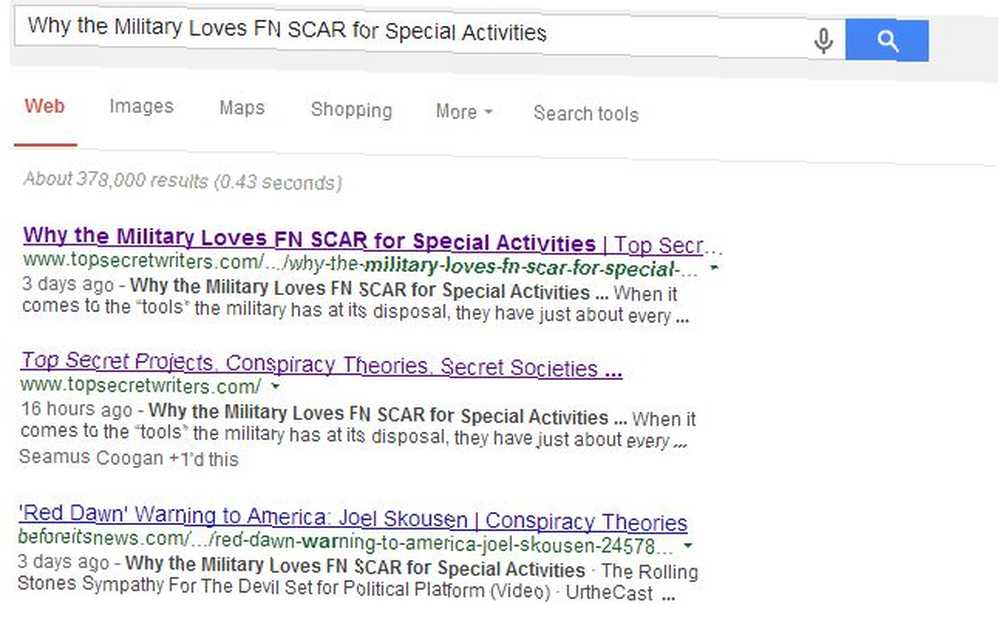
Pouze hlavní web přichází na třetí místo pro stránku, kde je uveden náš název, ale můj blog je nyní uveden na prvním i druhém místě; něco, co by bylo téměř nemožné, kdyby web s vyšší autoritou nechal duplikovanou stránku indexovanou.
Mnoho lidí si neuvědomuje, že toho lze dosáhnout také pomocí internetového archivu (Wayback Machine). Zde jsou řádky, které musíte přidat do souboru robots.txt, aby se tak stalo.
User-agent: ia_archiver Disallow: / sample-category /
V tomto příkladu říkám internetovému archivu, aby z Wayback Machine odstranil cokoli z podadresáře vzorové kategorie na mém webu. Internetový archiv vysvětluje, jak to provést na své stránce nápovědy pro vyloučení. Tady to také vysvětlují “Internetový archiv nemá zájem nabídnout přístup k webovým stránkám nebo jiným internetovým dokumentům, jejichž autoři nechtějí své materiály ve sbírce.”
To letí na rozdíl od běžně věřeného přesvědčení, že vše, co je zveřejněno na internetu, bude do věčnosti zameteno do archivu. Ne - webmasteři, kteří vlastní obsah, mohou obsah konkrétně odstranit z archivu pomocí přístupu robots.txt.
Odstraňte jednotlivou stránku se značkami metadat
Pokud máte pouze několik jednotlivých stránek, které chcete z výsledků vyhledávání Google odebrat, nemusíte vůbec používat přístup robots.txt, můžete jednoduše přidat správný “roboti” meta tag na jednotlivé stránky a řekněte robotům, aby neindexovali ani nesledovali odkazy na celé stránce.
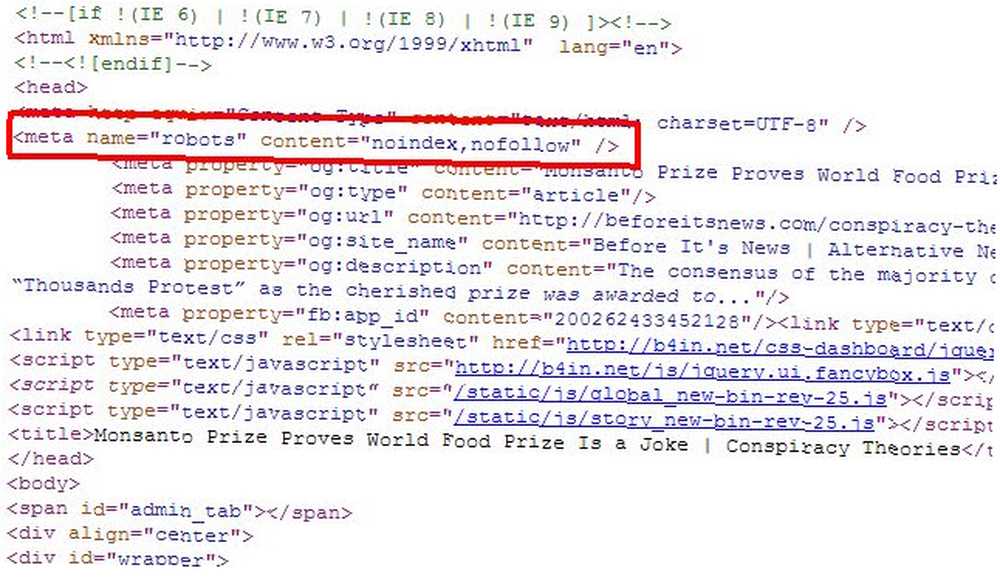
Dalo by se použít “roboti” meta výše, chcete-li zabránit robotům v indexování stránky, nebo můžete konkrétnímu robotovi Google říci, aby neindexoval, takže stránka je odebrána pouze z výsledků vyhledávání Google a další vyhledávací roboti by stále měli přístup k obsahu stránky.
Záleží jen na vás, jak chcete spravovat, co roboti dělají se stránkou, a zda se stránka zobrazí či nikoli. Pro několik samostatných stránek to může být lepší přístup. Chcete-li odebrat celý adresář obsahu, použijte metodu robots.txt.
Myšlenka “Odstraňuje se” Obsah
Tento druh otočí celou představu “mazání obsahu z internetu” na hlavě. Technicky, pokud odeberete všechny své vlastní odkazy na stránku na svém webu a odeberete ji z Vyhledávání Google a z internetového archivu technikou robots.txt, je stránka určena pro všechny účely a účely “smazáno” z internetu. Skvělá věc je, že pokud existují existující odkazy na stránku, tyto odkazy budou i nadále fungovat a nevyvoláte 404 chyb pro tyto návštěvníky.
Je to víc “jemný” přístup k odebírání obsahu z internetu, aniž by došlo k úplnému zpochybnění stávající popularity odkazů na vašem webu po celém internetu. Nakonec je na vás, jak postupujete při správě obsahu shromažďovaného pomocí vyhledávačů a internetového archivu, ale nezapomeňte, že navzdory tomu, co lidé říkají o životnosti věcí, které se zveřejňují online, je to opravdu pod vaší kontrolou..