











 Michael Cain
Michael Cain 0
0  5004
5004 247
247
Článek aktualizován Joel Lee dne 10. 10. 2017
Pro mnoho lidí, Google je internet. Je to výchozí bod pro hledání nových webů a je patrně nejdůležitější vynález od samotného internetu. Bez vyhledávačů by byl nový webový obsah pro masy nepřístupný.
Ale víte, jak fungují vyhledávače? Každý vyhledávač má tři hlavní funkce: procházení (objevování obsahu), indexování (sledování a ukládání obsahu) a vyhledávání (načítání relevantního obsahu, když uživatelé vyhledávají vyhledávací stroj).
Plazení
Procházení je místo, kde to všechno začíná: získávání údajů o webové stránce.
To zahrnuje skenování webů a shromažďování podrobností o každé stránce: tituly, obrázky, klíčová slova, jiné propojené stránky atd. Různé prolézací moduly mohou také hledat různé podrobnosti, jako je rozvržení stránky, kde jsou umístěny reklamy, zda jsou odkazy přeplněné atd..
Jak je však web procházen? Automatizovaný robot (nazývaný a “pavouk”) návštěvy stránky za stránkou co nejrychleji, pomocí odkazů na stránce zjistíte, kam dál. I v nejranějších dnech mohli pavouci Google přečíst několik stovek stránek za sekundu. Dnes je to v tisících.
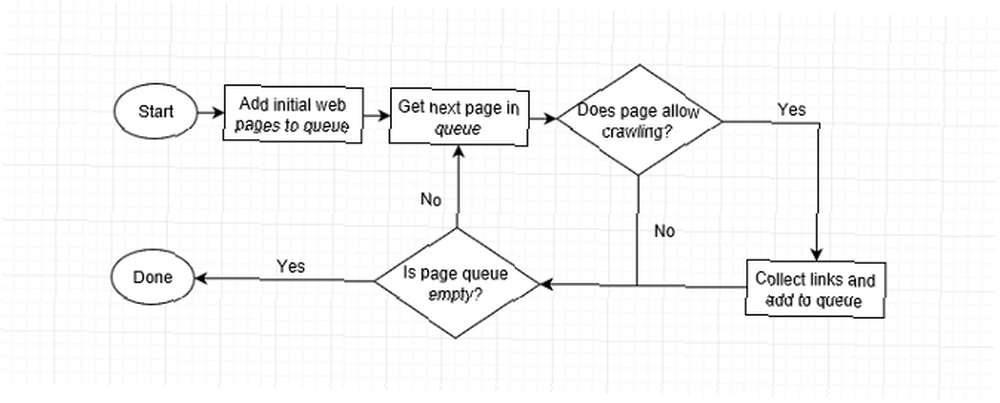
Když webový prolézací modul navštíví stránku, shromáždí každý odkaz na stránce a přidá je do seznamu dalších stránek, které chcete navštívit. Přejde na další stránku v seznamu, sbírá odkazy na že stránku a opakuje se. Webové prohledávače také jednou za čas revidují minulé stránky, aby zjistily, zda nedošlo ke změnám.
To znamená, že jakýkoli web propojený z indexovaného webu bude nakonec procházen. Některé weby jsou procházeny častěji a některé procházeny do větších hloubek, ale prolézací modul se někdy může vzdát, pokud je hierarchie stránek příliš složitá.
Jedním ze způsobů, jak porozumět tomu, jak webový prolézací modul funguje, je vytvořit si ho sami. Napsali jsme návod na vytvoření základního webového prolézacího modulu v PHP, takže se podívejte, jestli máte nějaké zkušenosti s programováním.

Upozorňujeme, že stránky lze označit jako “noindex,” což je jako požádat vyhledávače o přeskočení indexování. Neindexované části internetu jsou známé jako “hluboká síť” Co je to Deep Web? Je důležitější než si myslíte, co je to Deep Web? Je to důležitější než si myslíte Hluboký a tmavý web znějí strašidelně i nebezpečně, ale nebezpečí byla přehnaná. Zde je to, co ve skutečnosti jsou a jak k nim můžete přistupovat sami! a některé weby, jako jsou ty hostované v síti TOR, nemohou být vyhledávacími nástroji indexovány. (Co je směrování TOR a cibule? Co je směrování cibule, přesně? [MakeUseOf vysvětluje] Co je směrování cibule, přesně? [MakeUseOf vysvětluje] soukromí na internetu. Anonymita byla jednou z největších funkcí internetu v mládí (nebo jedním z jeho nejhorší rysy, v závislosti na tom, koho se zeptáte). Zanechte stranou nejrůznějších problémů, které vyvstávají…)
Indexování
Indexování je, když jsou data z procházení zpracována a umístěna do databáze.
Představte si, že vytvoříte seznam všech knih, které vlastníte, jejich vydavatelů, jejich autorů, jejich žánrů, počtu jejich stránek atd. Procházení je, když prolistujete každou knihu, zatímco indexování je, když je přihlásíte do svého seznamu..
Teď si představte, že to není jen místnost plná knih, ale každá knihovna na světě. Jedná se o malou verzi toho, co společnost Google dělá, a která všechna tato data ukládá v rozsáhlých datových centrech s tisíci petabajtů v hodnotě jednotek vysvětlujících paměťové velikosti: gigabajty, terabajty a petabajty v kontextu s kontextovou pamětí: gigabajty, terabajty a petabajty v kontextu Je snadno vidět, že 500 GB je více než 100 GB. Jak se však liší různé velikosti? Co je gigabajt pro terabajt? Kam se vejde petabyte? Pojďme to vyčistit! .
Zde je nahlédnutí do jednoho z vyhledávacích datových center Google:
 Obrázek Kredit: Google
Obrázek Kredit: Google
Získávání a hodnocení
Získání je, když vyhledávací stroj zpracuje váš vyhledávací dotaz a vrátí nejdůležitější stránky, které odpovídají vašemu dotazu.
Většina vyhledávačů se odlišuje svými metodami vyhledávání: používají různá kritéria pro výběr a výběr stránek, které nejlépe vyhovují tomu, co chcete najít. Proto se výsledky vyhledávání liší mezi Google a Bing a proč je Wolfram Alpha tak jedinečně užitečný 10 Cool použití Wolfram Alpha, pokud čtete a píšete v anglickém jazyce 10 Cool použití Wolfram Alpha, pokud čtete a píšete v anglickém jazyce mě nějaký čas obtočit hlavu kolem Wolfram Alpha a dotazy, které používá k hubení těchto výsledků. Musíte se ponořit hluboko do Wolfram Alpha, abyste to opravdu využili ... .
Algoritmy hodnocení porovnají váš vyhledávací dotaz miliard stránek, aby se určila relevance každého z nich. Společnosti chrání své hodnotící algoritmy jako patentovaná průmyslová tajemství kvůli své složitosti. Lepší algoritmus se promítá do lepšího vyhledávání.
Také nechtějí, aby si weboví tvůrci zahráli systém a nespravedlivě šplhali na vrchol výsledků vyhledávání. Pokud by se interní metodika vyhledávače někdy dostala ven, jistě by všichni lidé tuto znalost využili na úkor vyhledávačů, jako jste vy a já.
 Image Credit: photovibes via Shutterstock
Image Credit: photovibes via Shutterstock
Využití vyhledávače je samozřejmě, ale už to není tak snadné.
Vyhledávače původně hodnotily weby podle toho, jak často se na stránce objevila klíčová slova, což vedlo k “nádivka klíčového slova” - vyplňování stránek nesmysly těžkými klíčovými slovy.
Pak přišel koncept důležitosti odkazu: vyhledávače oceňují weby se spoustou příchozích odkazů, protože interpretovaly popularitu stránek jako relevanci. To však vedlo k propojení spamu na celém webu. V dnešní době, vyhledávače váha odkazy v závislosti na “autorita” odkazujícího webu. Vyhledávače dávají na odkazy z vládní agentury větší hodnotu než odkazy z adresáře odkazů.
Dnes jsou algoritmy klasifikace zahaleny tajemstvím více než kdy předtím, a “optimalizace vyhledávače” Demystify SEO: 5 průvodců optimalizace pro vyhledávače, které vám pomohou začít Demystify SEO: 5 průvodců optimalizace pro vyhledávače, které vám pomohou začít Zvládnutí vyhledávače vyžaduje znalosti, zkušenosti a spoustu pokusů a omylů. Můžete se začít učit základy a snadno se vyhnout běžným chybám SEO pomocí mnoha průvodců SEO dostupných na webu. není tak důležité. Kvalitní hodnocení vyhledávačů nyní vychází z vysoce kvalitního obsahu a skvělých uživatelských zkušeností.
Co bude dál pro vyhledávače?
Aha, teď je tu zajímavá otázka. Odpověď je “sémantika”: význam obsahu stránky. V našem přehledu sémantického značení a jeho budoucího dopadu se můžete dozvědět, co je sémantické značení a jak to navždy změní internet [vysvětlení technologie] Co je sémantické značení a jak to změní navždy internet [vysvětlení technologie] .
Ale tady je její podstata.
Právě teď můžete hledat “bezlepkové sušenky” ale výsledky mohou vrátit recepty na bezlepkové cookies. Místo toho můžete najít pravidelné recepty cookie, které říkají “Tento recept není bezlepkový.” Má správná klíčová slova, ale nesprávný význam.
Sémantika umožňuje vyhledávat recepty cookie a poté odebírat určité přísady: mouku, ořechy atd. Výsledky můžete také zúžit pouze na recepty s časy příprav kratšími než 30 minut a skóre skóre 4/5 nebo vyšší. Že by bylo super, že? Tam směřujeme!
Stále jste zmatení z toho, jak fungují vyhledávače? Podívejte se, jak Google vysvětluje tento postup:
Pokud vám to připadá zajímavé, můžete se také dozvědět, jak na to obraz fungují vyhledávače.
Obrázek Kredit: prykhodov / Depositphotos