











 Joseph Goodman
Joseph Goodman 0
0  5073
5073 1353
1353
Stále mluvíme o tom, jak nás počítače pochopí. Říkáme to Google “věděl” co jsme hledali, nebo to Cortana “dostal” co jsme říkali, ale “porozumění” je velmi obtížný koncept. Zvláště pokud jde o počítače.
Jedna oblast počítačové lingvistiky, nazvaná zpracování přirozeného jazyka (NLP), pracuje na tomto obzvláště těžkém problému. Právě teď je to fascinující pole a až budete mít představu o tom, jak to funguje, začnete vidět jeho účinky všude.
Rychlá poznámka: Tento článek obsahuje několik příkladů, jak počítač reaguje na řeč, například když o něco požádáte Siriho. Transformace slyšitelné řeči do počítačově srozumitelného formátu se nazývá rozpoznávání řeči. NLP se tím netýká (přinejmenším v kapacitě, o které zde diskutujeme). NLP vstoupí do hry, jakmile je text připraven. Oba procesy jsou nezbytné pro mnoho aplikací, ale jsou to dva velmi odlišné problémy.
Definování porozumění
Než se dostaneme k tomu, jak počítače řeší přirozený jazyk, musíme definovat několik věcí.
Nejprve musíme definovat přirozený jazyk. Je to snadné: každý jazyk, který lidé pravidelně používají, spadá do této kategorie. Nezahrnuje věci jako konstruované jazyky (Klingon, esperanto) nebo počítačové programovací jazyky. Při rozhovoru se svými přáteli používáte přirozený jazyk. Pravděpodobně jej také používáte při rozhovoru s digitálním osobním asistentem.
Co máme na mysli, když říkáme porozumění? Je to složité. Co to znamená rozumět větě? Možná byste řekli, že to znamená, že nyní máte v mozku zamýšlený obsah zprávy. Pochopení pojmu může znamenat, že ho můžete použít i na jiné myšlenky.
Definice slovníku jsou mlhavé. Neexistuje žádná intuitivní odpověď. Filozofové se o věci, jako je toto, hádají po celá staletí.
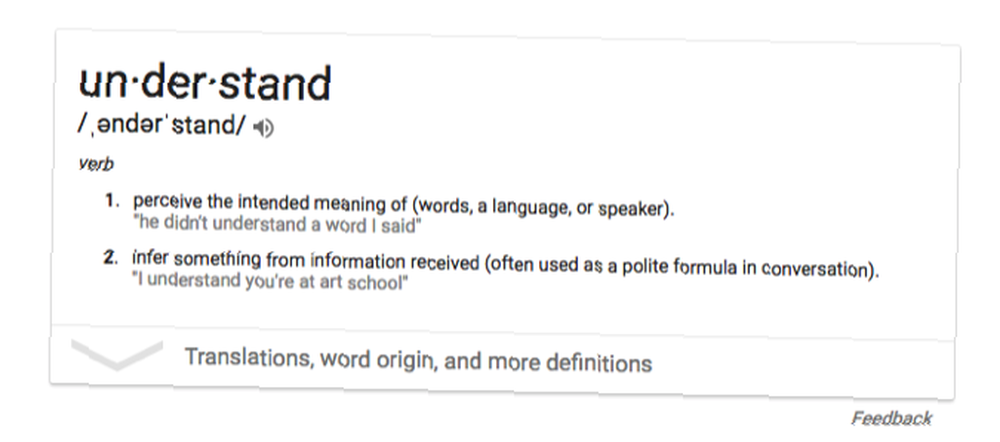
Pro naše účely řekneme, že chápání je schopnost přesně extrahovat význam z přirozeného jazyka. Aby počítač pochopil, musí přesně zpracovat příchozí proud řeči, převést tento proud na jednotky významu a být schopen reagovat na vstup pomocí něčeho, co je užitečné.
Samozřejmě je to všechno velmi vágní. Ale je to nejlepší, co můžeme udělat s omezeným prostorem (a bez stupně neurofilosofie). Pokud počítač může nabídnout lidskou nebo přinejmenším užitečnou odpověď na proud přirozeného jazyka, můžeme říci, že tomu rozumí. Toto je definice, kterou budeme používat vpřed.
Složitý problém
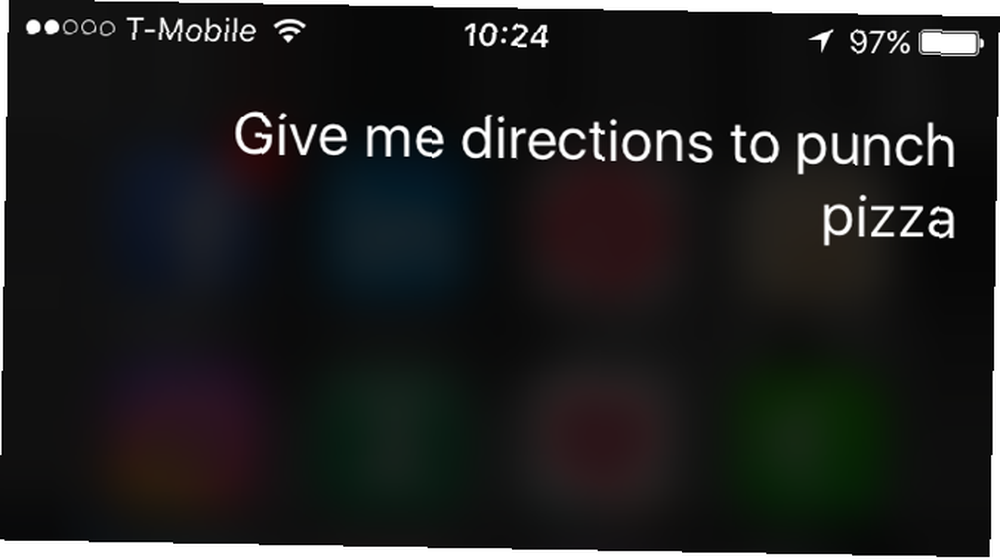
Přirozený jazyk je pro počítač velmi obtížný. Dalo by se říct, “Siri, dejte mi pokyny k Punch Pizza,” zatímco bych mohl říct, “Siri, Punch Pizza, prosím.”
Ve tvém prohlášení by si Siri mohl vybrat frázi “dejte mi pokyny,” pak spusťte příkaz související s hledaným výrazem “Punch Pizza.” V mém však musí Siri vybírat “trasa” jako klíčové slovo a vědět to “Punch Pizza” je místo, kam chci jít, ne “prosím.” A to je jen zjednodušující příklad.
Přemýšlejte o umělé inteligenci, která čte e-maily a rozhoduje, zda to mohou být podvody. Nebo ten, který monitoruje příspěvky sociálních médií, aby zjistil zájem o konkrétní společnost. Jednou jsem pracoval na projektu, kde jsme museli učit počítač číst lékařské poznámky (které mají nejrůznější podivné konvence) a získávat z nich informace.
To znamená, že systém musel být schopen vypořádat se zkratkami, podivnou syntaxí, příležitostnými překlepy a celou řadou dalších rozdílů v poznámkách. Je to velmi složitý úkol, který může být obtížný i pro zkušené lidi, mnohem méně strojů.
Nastavení příkladu
V tomto konkrétním projektu jsem byl součástí týmu, který učil počítač rozpoznávat konkrétní slova a vztahy mezi slovy. Prvním krokem procesu bylo ukázat počítači informace, které každá poznámka obsahovala, a proto jsme poznámky anotovali.
Existovalo obrovské množství různých kategorií entit a vztahů. Vezměte si větu “Bolest hlavy paní Greenové byla léčena ibuprofenem,” například. Paní Greenová byl označen jako OSOBA, bolest hlavy byl označen jako SIGNÁL NEBO SYMPTOM, ibuprofen byl označen jako MEDICATION. Pak byla paní Greenová spojena s bolestmi hlavy s přítomností vztahu. Nakonec byl ibuprofen spojen s bolestmi hlavy pomocí vztahu TREATS.

Tímto způsobem jsme označili tisíce poznámek. Zakódovali jsme diagnózy, léčbu, symptomy, základní příčiny, komorbidity, dávky a vše ostatní, o čem byste si mohli myslet, že se týkají medicíny. Další anotační týmy kódovaly další informace, například syntaxi. Nakonec jsme měli korpus plný lékařských poznámek, které umělá inteligence mohla “číst.”
Čtení je stejně těžké definovat jako porozumění. Počítač snadno vidí, že ibuprofen zachází s bolestmi hlavy, ale když se tyto informace učí, převede se na ty bezvýznamné (na nás) a nula. Určitě to může poskytnout informace, které se zdají být podobné člověku a jsou užitečné, ale tvoří to porozumění Co umělá inteligence není Co umělá inteligence není Inteligentní, vnímající roboti přebírají svět? Ne dnes - a možná ne nikdy. ? Je to opět filozofická otázka.
Skutečné učení
V tomto okamžiku počítač prošel poznámkami a použil řadu algoritmů strojového učení 4 Algoritmy strojového učení, které tvarují váš život 4 Algoritmy strojového učení, které tvarují váš život Možná si to neuvědomujete, ale strojové učení je již všude kolem vás a může to mít překvapivý vliv na váš život. Nevěříš mi? Možná vás překvapí. . Programátoři vyvinuli různé rutiny pro značkování částí řeči, analýzu závislostí a volebních obvodů a označování sémantických rolí. AI se v podstatě učila “číst” poznámky.
Vědci by to mohli nakonec vyzkoušet tak, že mu dají lékařskou poznámku a požádají ji, aby označili jednotlivé entity a vztahy. Když počítač přesně reprodukoval lidské poznámky, můžete říci, že se naučil číst uvedené lékařské poznámky.
Poté bylo jen otázkou shromáždění velkého množství statistik o tom, co četl: jaké drogy se používají k léčbě poruch, které léčby jsou nejúčinnější, základní příčiny specifických příznaků atd. Na konci procesu by umělá inteligence mohla odpovědět na lékařské otázky na základě důkazů ze skutečných lékařských poznámek. Nemusí se spoléhat na učebnice, farmaceutické společnosti nebo intuici.
Hluboké učení
Podívejme se na další příklad. Neuronová síť Google DeepMind se učí číst novinové články. Stejně jako výše uvedená biomedicínská umělá inteligence vědci chtěli, aby z větších textů vytáhlo relevantní a užitečné informace.
Výcvik umělé inteligence na lékařské informace byl dost tvrdý, takže si dokážete představit, kolik anotovaných dat potřebujete, aby umělá inteligence mohla číst obecné zpravodajské články. Najmout dostatek anotátorů a dostatek informací by bylo neúměrně nákladné a časově náročné.
Tým DeepMind se tedy obrátil na jiný zdroj: zpravodajské weby. Konkrétně CNN a denní pošta.
Proč tyto stránky? Protože poskytují shrnutí článků s odrážkami, které jednoduše nevytahují věty ze samotného článku. To znamená, že AI má co učit. Vědci v podstatě řekli AI, “Zde je článek a zde jsou nejdůležitější informace v něm.” Potom ho požádali, aby z článku vytáhl stejný typ informací bez odrážek.
Tuto úroveň složitosti může zvládnout hluboká neuronová síť, což je obzvláště komplikovaný typ systému strojového učení. (Tým DeepMind dělá na tomto projektu několik úžasných věcí. Chcete-li získat specifika, podívejte se na tento skvělý přehled z MIT Technology Review.)
Co umí AI pro čtení?
Nyní máme obecné znalosti o tom, jak se počítače učí číst. Berete velké množství textu, řeknete počítači, co je důležité, a aplikujete některé algoritmy strojového učení. Co však můžeme dělat s umělou inteligencí, která vytáhne informace z textu?
Už víme, že z lékařských poznámek si můžete vytáhnout konkrétní informace, které lze použít, a shrnout obecné zpravodajské články. Existuje open-source program s názvem P.A.N. která analyzuje poezii vytažením témat a snímků. Vědci často používají strojové učení k analýze velkých skupin dat sociálních médií, která společnosti používají k porozumění sentimentům uživatelů, k tomu, o čem lidé mluví, a k nalezení užitečných vzorců pro marketing.
Vědci použili strojové učení k nahlédnutí do chování při zasílání e-mailů a účinků přetížení e-mailem. Poskytovatelé e-mailu jej mohou použít k odfiltrování nevyžádané pošty ze své doručené pošty a klasifikovat některé zprávy jako vysoce prioritní. Čtení AIs je rozhodující pro efektivní chatování u zákazníka 8 botů, které byste měli přidat do aplikace Facebook Messenger 8 botů, které byste měli přidat do aplikace Facebook Messenger Facebook Messenger se otevřel chatovacím robotům, což společnostem umožňuje poskytovat zákaznický servis, zprávy a další přímo vám prostřednictvím aplikace. Zde jsou některé z nejlepších dostupných. . Kdekoli je text, existuje výzkumný pracovník, který pracuje na zpracování přirozeného jazyka.
A jak se tento typ strojového učení zlepšuje, možnosti se jen zvyšují. Počítače jsou nyní v šachu, Go a videohrách lepší než lidé. Brzy mohou být lepší při čtení a učení. Je to první krok k silné umělé inteligenci. Zde je důvod, proč si vědci myslí, že byste se měli obávat umělé inteligence. Zde je důvod, proč si vědci myslí, že byste se měli obávat umělé inteligence. Myslíte si, že umělá inteligence je nebezpečná? Může AI představovat vážné riziko pro lidskou rasu. To jsou některé důvody, proč byste měli mít obavy. ? Budeme muset počkat a uvidíme, ale může to být.
Jaký druh využití vidíte pro AI pro čtení a učení textu? Jaké druhy strojového učení si myslíte, že uvidíme v blízké budoucnosti? Podělte se o své myšlenky v komentářích níže!
Obrazové kredity: Vasilyev Alexandr / Shutterstock