











 Michael Fisher
Michael Fisher 0
0  4614
4614 250
250
Webové škrabky automaticky shromažďuje informace a data, která jsou obvykle přístupná pouze návštěvou webových stránek v prohlížeči. Tím, že to provedete autonomně, skripty pro webový škrabání otevírají svět možností v těžbě dat, analýze dat, statistické analýze a mnohem více.
Proč je užitečný nástroj Web Scraping
Žijeme v den a věku, kdy jsou informace snadněji dostupné než kdykoli jindy. Infrastruktura používaná k poskytování těchto samotných slov, která čtete, vede k většímu poznání, názorům a zprávám, než kdy byly lidem v historii lidí přístupné.
Ve skutečnosti natolik, že mozek nejchytřejší osoby, vylepšený na 100% účinnost (o tom by měl někdo natočit film), by stále nebyl schopen zadržet 1/1 000 dat uložených na internetu pouze ve Spojených státech..
Společnost Cisco v roce 2016 odhadovala, že provoz na internetu překročil jeden zettabajt, což je 1 000 000 000 000 000 000 000 bajtů, nebo jeden sextillion bajtů (pokračujte, chichotejte se sextillionem). Jeden zettabyte je asi čtyři tisíce let streamování Netflixu. To by bylo ekvivalentní tomu, kdybyste vy, intrepidní čtenáři streamovali kancelář od začátku do konce bez zastavení 500 000krát.
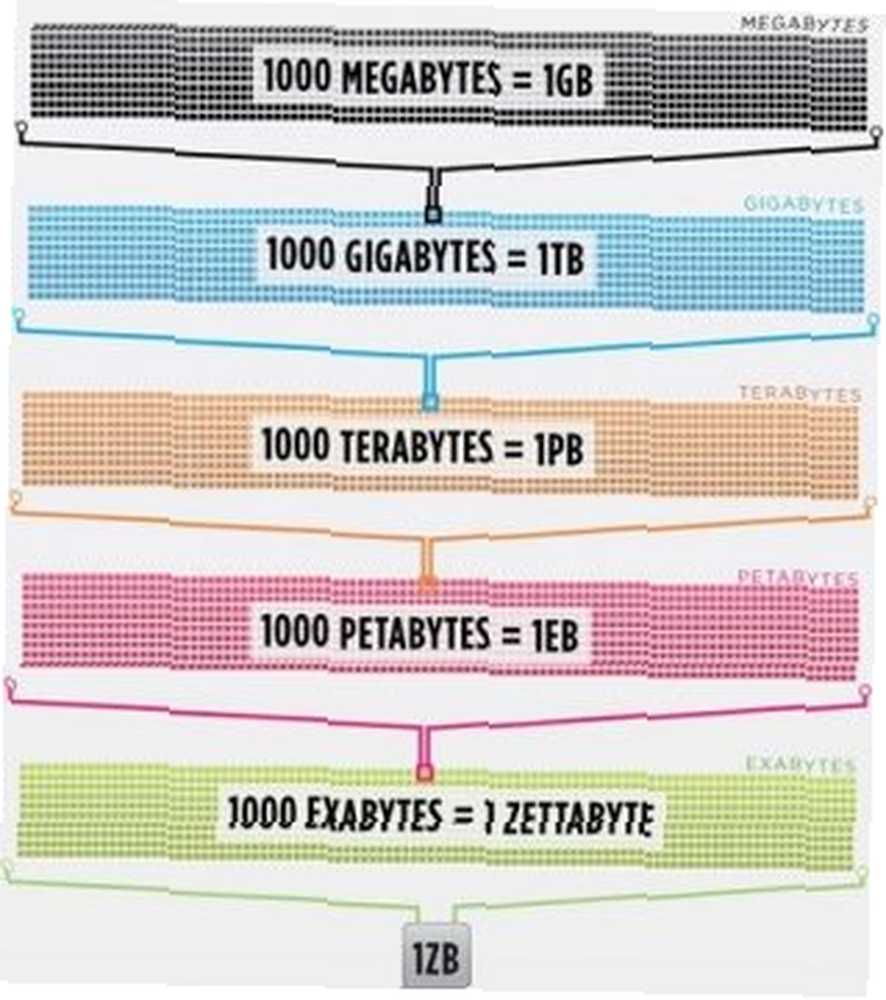 Image Credit: Cisco / The Dawn of Zettabyte
Image Credit: Cisco / The Dawn of Zettabyte
Všechna tato data a informace jsou velmi zastrašující. Ne všechno je správné. Není to moc důležité pro každodenní život, ale stále více zařízení dodává tyto informace ze serverů po celém světě přímo do našich očí a do našich mozků..
Protože naše oči a mozky nemohou všechny tyto informace opravdu zpracovat, objevilo se webové škrabání jako užitečná metoda pro programové shromažďování dat z internetu. Scraping webu je abstraktní pojem, který definuje akt extrahování dat z webových stránek, aby se uložil místně.
Přemýšlejte o typu dat a pravděpodobně je můžete sbírat škrábáním webu. Seznamy nemovitostí, sportovní údaje, e-mailové adresy podniků ve vaší oblasti a dokonce i texty od vašeho oblíbeného umělce lze vyhledávat a ukládat psáním malého skriptu.
Jak prohlížeč získává webová data?
Abychom porozuměli webovým škrabkám, musíme nejprve pochopit, jak web funguje. Chcete-li se dostat na tento web, zadejte buď “makeuseof.com” do webového prohlížeče nebo klikli jste na odkaz z jiné webové stránky (řekněte nám, kde to opravdu chceme vědět). V obou případech je následujících pár kroků stejné.
Nejprve prohlížeč vezme adresu URL, kterou jste zadali nebo na kterou jste klikli (Pro-tip: najeďte kurzorem na odkaz, abyste viděli adresu URL v dolní části prohlížeče, než na ni kliknete, abyste se vyhnuli punk'd) a vytvořte “žádost” poslat na server. Server poté žádost zpracuje a odešle odpověď zpět.
Odpověď serveru obsahuje HTML, JavaScript, CSS, JSON a další data potřebná k tomu, aby váš webový prohlížeč mohl vytvořit webovou stránku pro vaše potěšení ze sledování.
Kontrola webových prvků
Moderní prohlížeče nám umožňují některé podrobnosti týkající se tohoto procesu. V prohlížeči Google Chrome v systému Windows můžete stisknout tlačítko Ctrl + Shift + I nebo klikněte pravým tlačítkem a vyberte Kontrolovat. V okně se zobrazí obrazovka, která vypadá následovně.
V horní části okna je řádek se seznamem voleb. Zajímavé právě teď je Síť tab. Tím získáte podrobnosti o provozu HTTP, jak je uvedeno níže.
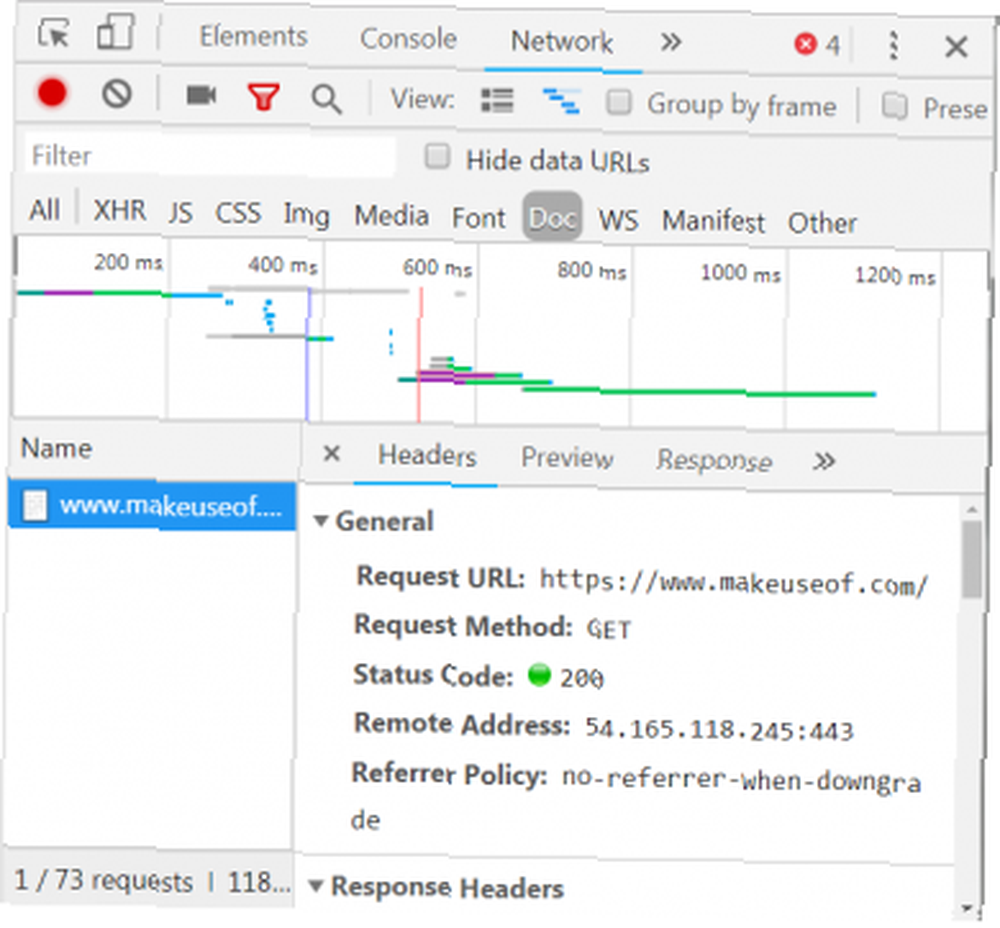
V pravém dolním rohu vidíme informace o požadavku HTTP. URL je to, co očekáváme, a “metoda” je HTTP “DOSTAT” žádost. Stavový kód z odpovědi je uveden jako 200, což znamená, že server viděl požadavek jako platný.
Pod stavovým kódem je vzdálená adresa, což je veřejná IP adresa serveru makeuseof.com. Klient získá tuto adresu prostřednictvím protokolu DNS Proč změna nastavení DNS zvyšuje rychlost Internetu Proč změna nastavení DNS zvyšuje rychlost Internetu Změna nastavení DNS je jedním z těch drobných vylepšení, které mohou mít velký návrat ke každodenním internetovým rychlostem.. .
V další části jsou uvedeny podrobnosti o odpovědi. Záhlaví odpovědi obsahuje nejen stavový kód, ale také typ dat nebo obsahu, který odpověď obsahuje. V tomto případě se na to díváme “text / html” se standardním kódováním. To nám říká, že odpověď je doslova HTML kód pro vykreslení webu.
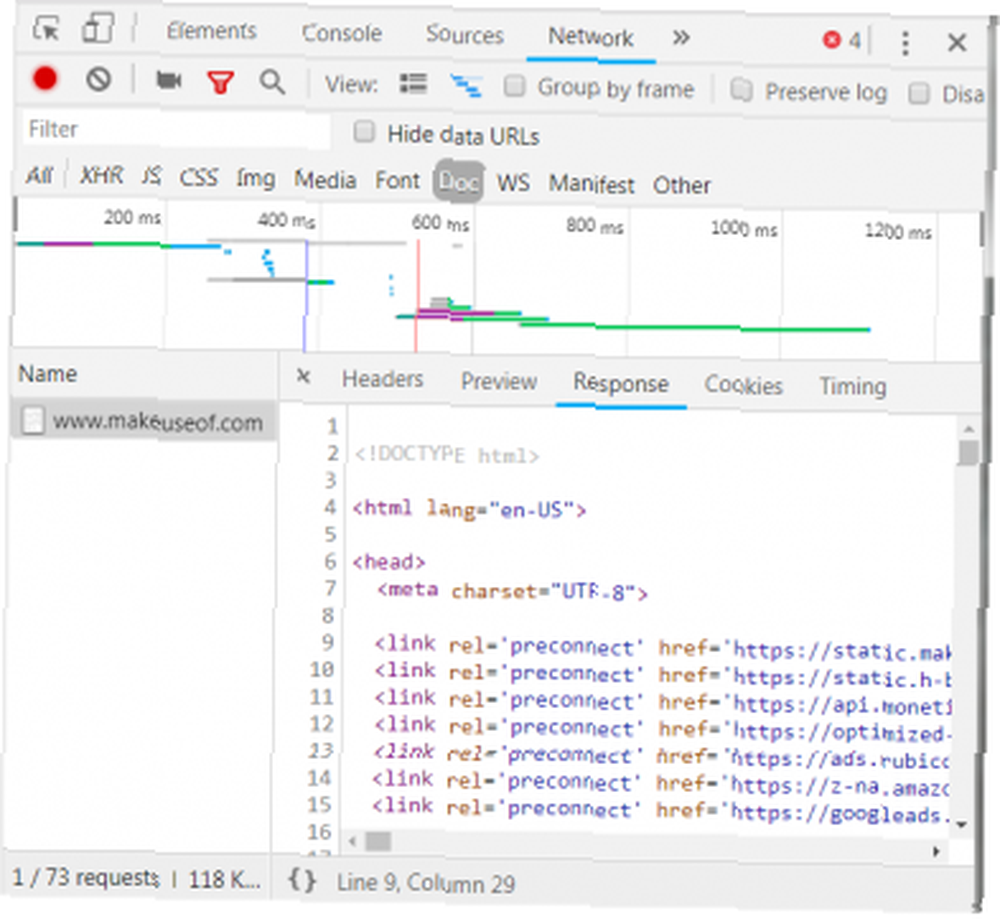
Další typy odpovědí
Servery mohou navíc vracet datové objekty jako odpověď na požadavek GET, nikoli pouze HTML pro vykreslení webové stránky. Webové aplikační programové rozhraní (nebo API) Co jsou API a jak otevřená API mění internet Co jsou API a jak otevřená API mění internet Už jste někdy přemýšleli, jak programy v počítači a webové stránky, které navštěvujete „talk“ navzájem? obvykle používá tento typ výměny.
Když si prohlédnete kartu Síť, jak je ukázáno výše, uvidíte, zda se jedná o tento typ výměny. Při zkoumání CrossFit Open Leaderboard se zobrazí žádost o vyplnění tabulky údaji.
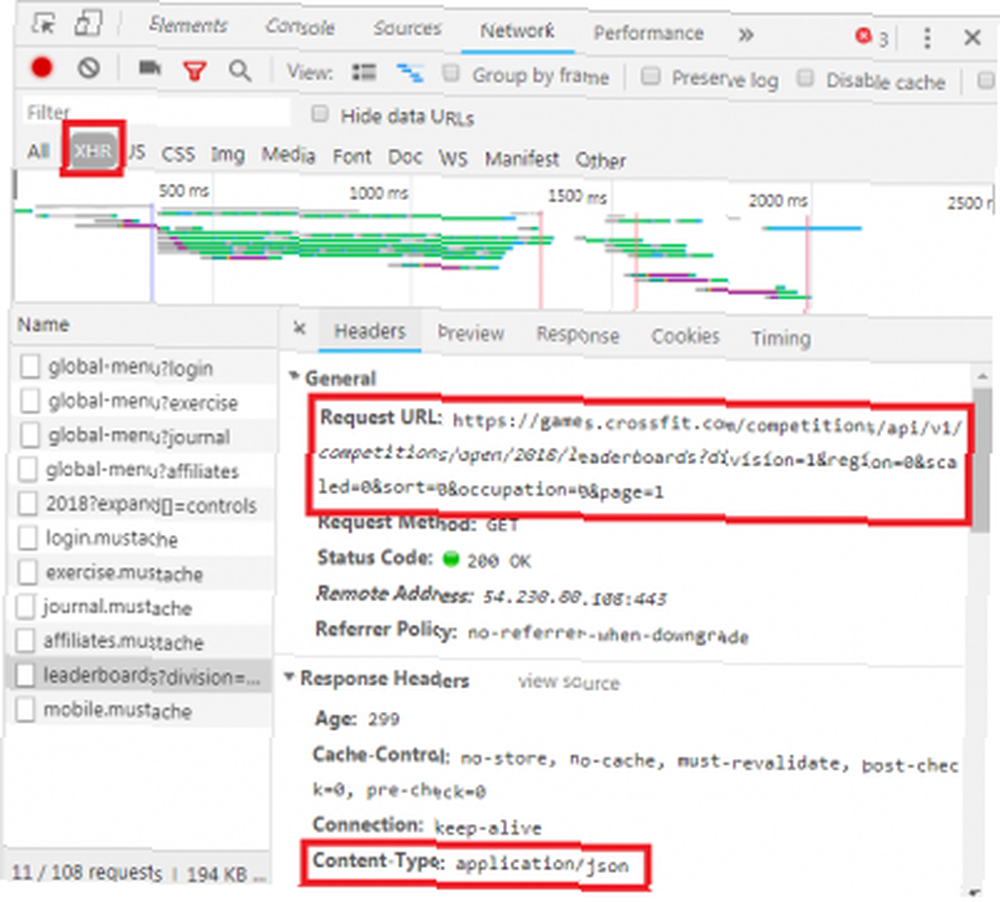
Kliknutím na odpověď se zobrazí data JSON namísto kódu HTML pro vykreslení webu. Data v JSON je řada štítků a hodnot ve vrstveném, nastíněném seznamu.
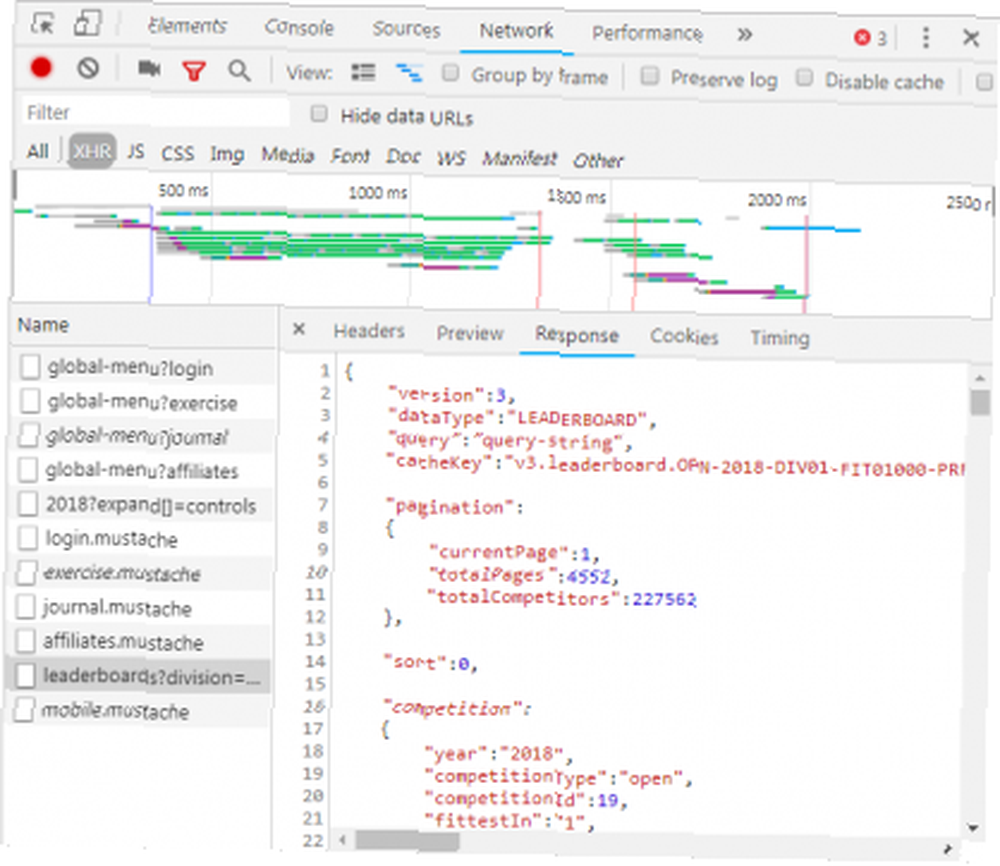
Ruční analýza kódu HTML nebo procházení tisíců párů klíč / hodnota JSON je hodně podobné čtení Matice. Na první pohled to vypadá jako blábol. Může být příliš mnoho informací pro ruční dekódování.
Web Scrapers k záchraně!
Nyní, než začnete žádat o modrou pilulku, abyste odtud dostali sakra, měli byste vědět, že nemusíme ručně dekódovat HTML kód! Neznalost není blažená a tento steak je Lahodné.
Web škrabka může tyto obtížné úkoly provádět. Scrapingové rámce jsou k dispozici v Pythonu, JavaScriptu, Uzlu a dalších jazycích. Jedním z nejjednodušších způsobů, jak začít se škrabáním, je použití Pythonu a krásné polévky.
Škrábání webových stránek pomocí Pythonu
Začínáme trvá jen několik řádků kódu, pokud máte nainstalovaný Python a BeautifulSoup. Zde je malý skript pro získání zdroje webové stránky a nechat jej vyhodnotit BeautifulSoup.
from bs4 import BeautifulSoup požadavky na import url = "http://www.athleticvolume.com/programming/" content = request.get (url) soup = BeautifulSoup (content.text) tisk (polévka) Velmi jednoduše děláme GET požadavek na URL a poté vložíme odpověď do objektu. Tisk objektu zobrazí zdrojový kód HTML adresy URL. Tento proces je stejný, jako kdybychom šli ručně na web a klikli Zobrazit zdroj.
Konkrétně se jedná o web, který zveřejňuje tréninky ve stylu CrossFit každý den, ale pouze jeden za den. Můžeme sestavit naši škrabku, abychom dostali trénink každý den, a poté jej přidat do souhrnného seznamu tréninků. V zásadě můžeme vytvořit textovou historickou databázi cvičení, pomocí kterých můžeme snadno procházet.
Kouzlo BeaufiulSoup je schopnost prohledávat celý HTML kód pomocí vestavěné funkce findAll (). V tomto konkrétním případě web používá několik “sqs-block-content” značky. Skript proto musí procházet všemi těmito značkami a najít tu, která je pro nás zajímavá.
Kromě toho existuje celá řada
značky v sekci. Skript může přidat veškerý text z každé z těchto značek do lokální proměnné. Chcete-li to provést, přidejte do skriptu jednoduchou smyčku:
pro div_class v soup.findAll ('div', 'class': 'sqs-block-content'): recordThis = False pro p v div_class.findAll ('p'): pokud 'PROGRAM' v p.text. upper (): recordThis = True, pokud recordThis: program + = p.text program + = '\ n' Voilà! Narodila se webová škrabka.
Scaling Up Scraping
K pohybu vpřed existují dvě cesty.
Jedním ze způsobů, jak prozkoumat škrabání na webu, je použití již vytvořených nástrojů. Web Scraper (skvělé jméno!) Má 200 000 uživatelů a je snadno použitelný. Rovněž Parse Hub umožňuje uživatelům exportovat poškrábaná data do Excelu a Tabulek Google.
Web Scraper navíc obsahuje plug-in Chrome, který pomáhá vizualizovat, jak je web vytvořen. Nejlepší ze všeho, soudě podle jména, je OctoParse, silný škrabka s intuitivním rozhraním.
A konečně, teď, když znáte pozadí webového škrabání, pozvednete svůj malý malý webový škrabák, abyste mohli procházet a spouštět Jak vytvořit základní webový prohledávač pro vytažení informací z webu Jak vytvořit základní webový prohledávač pro vytažení informací z Webová stránka Už jste někdy chtěli zachytit informace z webové stránky? Můžete napsat prolézací modul pro procházení webu a extrahovat přesně to, co potřebujete. sám o sobě je zábavné úsilí.