











 Michael Cain
Michael Cain 0
0  2485
2485 116
116
Microsoft Excel je aplikace pro každého, kdo musí pracovat se spoustou čísel, od studentů po účetní. Jeho užitečnost však přesahuje rozsáhlé databáze Excel Vs. Přístup - Může tabulku nahradit databázi? Excel Vs. Přístup - Může tabulku nahradit databázi? Jaký nástroj byste měli použít ke správě dat? Aplikace Access a Excel obsahují funkce filtrování dat, řazení a dotazování. Ukážeme vám, který z nich je pro vaše potřeby nejvhodnější. ; s textem může také dělat spoustu skvělých věcí. Níže uvedené funkce vám pomohou analyzovat, upravovat, převádět a jinak provádět změny v textu - a ušetřit tak mnoho hodin nudné a opakující se práce.
Tato příručka je k dispozici ke stažení jako PDF zdarma. Stáhněte si nyní šetřící čas pomocí textových operací v Excelu. Neváhejte jej zkopírovat a sdílet se svými přáteli a rodinou.Navigace: Nedestruktivní úpravy | Poloviční a plné šířky znaků | Znakové funkce Funkce pro analýzu textu Funkce převodu textu Funkce úpravy textu Funkce nahrazení textu Funkce vytváření textu Příklad ze skutečného světa
Nedestruktivní úpravy
Jedním z principů použití textových funkcí Excelu je princip nedestruktivních úprav. Jednoduše řečeno to znamená, že pokaždé, když pomocí funkce provedete změnu textu v řádku nebo sloupci, zůstane tento text nezměněn a nový text bude umístěn do nového řádku nebo sloupce. Zpočátku to může být trochu dezorientující, ale může to být velmi cenné, zejména pokud pracujete s obrovskou tabulkou, kterou by bylo obtížné nebo nemožné rekonstruovat v případě, že by se editace pokazila.
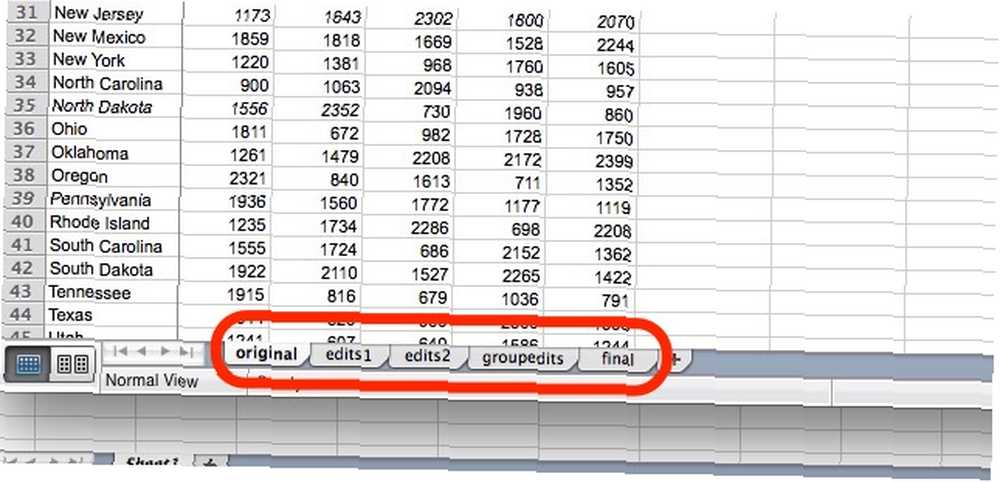
I když můžete i nadále přidávat sloupce a řádky do své neustále se rozšiřující obří tabulky, jedním ze způsobů, jak toho využít, je uložit původní tabulku do prvního listu v dokumentu a následné upravené kopie do dalších listů. Tímto způsobem, bez ohledu na to, kolik úprav provedete, budete mít vždy původní data, ze kterých pracujete.
Znaky s poloviční a celou šířkou
Některé z funkcí, které jsou zde popsány, odkazují na jedno- a dvoubajtové znakové sady, a než začneme, bude užitečné objasnit, co přesně jsou. V některých jazycích, jako je čínština, japonština a korejština, bude mít každý znak (nebo několik znaků) dvě možnosti zobrazení: jeden, který je kódován ve dvou bajtech (známý jako znak s plnou šířkou), a druhý, který je kódován v jeden bajt (poloviční šířka). Rozdíl v těchto postavách můžete vidět zde:

Jak vidíte, jsou dvoubajtové znaky větší a často i lépe čitelné. V některých výpočetních situacích je však vyžadován jeden nebo druhý z těchto typů kódování. Pokud nevíte, co to všechno znamená nebo proč byste se s tím měli bát, je velmi pravděpodobné, že to není něco, na co nebudete muset myslet. V případě, že tak učiníte, jsou však v následujících sekcích obsaženy funkce, které se vztahují konkrétně na znaky poloviční a plné šířky.
Znakové funkce
Není to často, že pracujete s jednotlivými postavami v Excelu, ale tyto situace se občas objevují. A když ano, tyto funkce jsou ty, které potřebujete vědět.
Funkce CHAR a UNICHAR
CHAR vezme číslo znaku a vrátí odpovídající znak; pokud máte například seznam čísel znaků, CHAR vám pomůže je převést na znaky, na které jste zvyklí. Syntaxe je celkem jednoduchá:
= CHAR ([text])
[text] může mít formu odkazu na buňku nebo znaku; takže = CHAR (B7) a = CHAR (84) fungují. Pamatujte, že při používání funkce CHAR se použije kódování, na kterém je počítač nastaven; takže váš = CHAR (84) se může lišit od mého (zejména pokud používáte počítač se systémem Windows, protože používám Excel pro Mac).

Pokud je číslo, na které převádíte, číslo znaku Unicode a používáte Excel 2013, budete muset použít funkci UNICHAR. Předchozí verze aplikace Excel tuto funkci nemají.
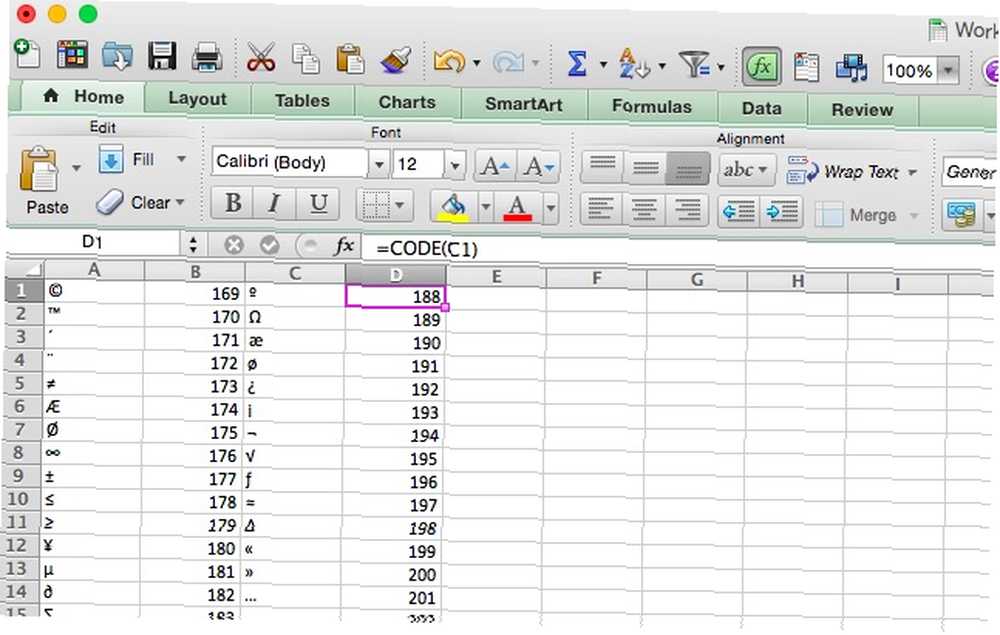
Funkce CODE a UNICODE
Jak byste mohli očekávat, CODE a UNICODE provádějí přesný opak funkcí CHAR a UNICHAR: vezmou znak a vrátí číslo pro kódování, které jste si vybrali (nebo které je ve vašem počítači nastaveno na výchozí). Důležité je mít na paměti, že pokud tuto funkci spustíte na řetězci, který obsahuje více než jeden znak, vrátí pouze odkaz na první znak v řetězci. Syntaxe je velmi podobná:
= KÓD ([text])
V tomto případě je [text] znak nebo řetězec. A pokud chcete místo výchozího počítače odkaz na Unicode, použijete UNICODE (znovu, pokud máte Excel 2013 nebo novější).
Funkce pro analýzu textu
Funkce v této části vám pomohou získat informace o textu v buňce, což může být užitečné v mnoha situacích. Začneme se základy.
Funkce LEN
LEN je velmi jednoduchá funkce: vrací délku řetězce. Takže pokud potřebujete spočítat počet písmen v banda různých buněk, je to způsob, jak jít. Zde je syntax:
= LEN ([text])
Argument [text] je buňka nebo buňky, které chcete počítat. Níže vidíte, že pomocí funkce LEN na buňce, která obsahuje název města “Austin,” vrátí se 6. Když se použije na název města “South Bend,” vrátí se 10. Mezera se počítá jako postava s LEN, takže mějte na paměti, pokud ji používáte k výpočtu počtu písmen v dané buňce.
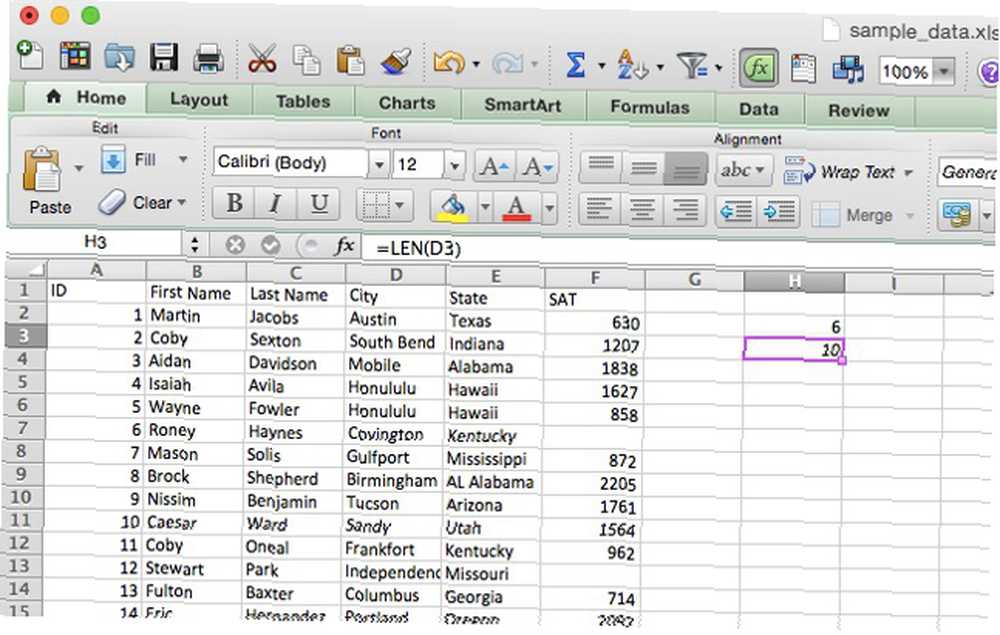
Související funkce LENB provádí totéž, ale pracuje s dvoubajtovými znaky. Pokud byste měli počítat sérii čtyř dvoubajtových znaků pomocí LEN, výsledek by byl 8. Při LENB je to 4 (pokud máte jako výchozí jazyk povolen DBCS).
Funkce FIND
Možná se divíte, proč byste použili funkci nazvanou FIND, pokud můžete použít pouze CTRL + F nebo Úpravy> Najít. Odpověď spočívá ve specifičnosti, se kterou můžete pomocí této funkce hledat; místo prohledávání celého dokumentu si můžete vybrat, u kterého znaku každého řetězce bude vyhledávání zahájeno. Syntaxe pomůže objasnit tuto matoucí definici:
= FIND ([find_text], [inside_text], [start_num])
[find_text] je řetězec, který hledáte. [uvnitř_text] je buňka nebo buňky, ve kterých Excel bude hledat tento text, a [start_num] je první znak, na který se bude dívat. Je důležité si uvědomit, že tato funkce rozlišuje velká a malá písmena. Vezměme si příklad.
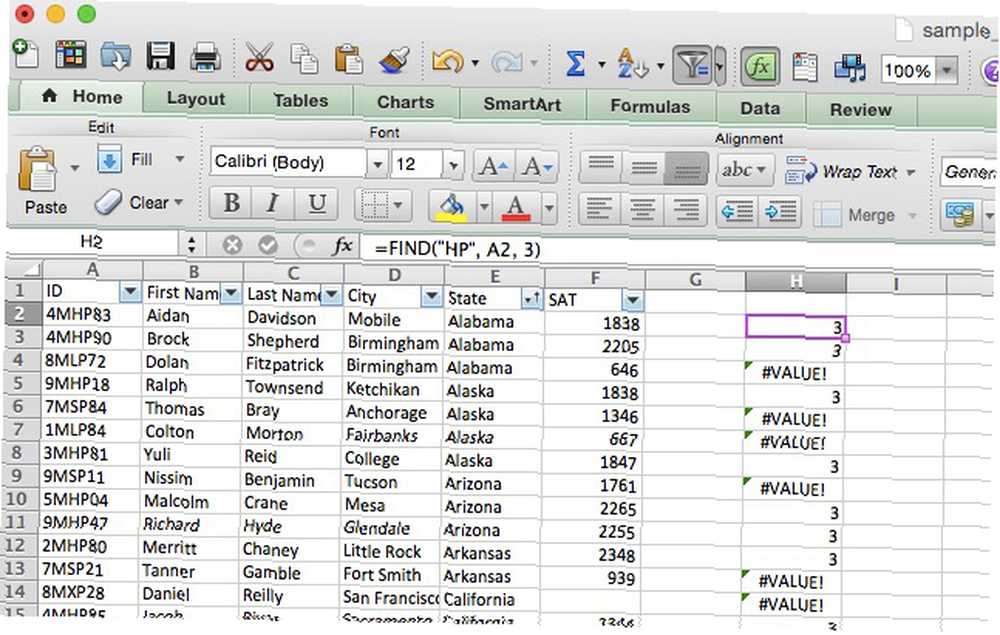
Aktualizoval jsem vzorová data tak, že ID číslo každého studenta je šestimístná alfanumerická sekvence, z nichž každá začíná jednou číslicí, M pro “mužský,” posloupnost dvou písmen označující úroveň výkonu studenta (HP pro vysokou, SP pro standardní, LP pro nízkou a UP / XP pro neznámou) a konečnou sekvenci dvou čísel. Pojďme použít FIND k zvýraznění každého vysoce výkonného studenta. Zde je syntaxe, kterou použijeme:
= FIND („HP“, A2, 3)
To nám řekne, zda se HP objeví po třetím znaku buňky. Při použití na všechny buňky ve sloupci ID můžeme na první pohled vidět, zda byl student vysoce výkonný nebo ne (všimněte si, že 3 vrácená funkcí je znak, u kterého je HP nalezena). Najít můžete lépe využít, pokud máte širší škálu sekvencí, ale získáte představu.
Stejně jako u LEN a LENB se FINDB používá pro stejný účel jako FIND, pouze u dvojbajtových znakových sad. To je důležité kvůli specifikaci určitého charakteru. Pokud používáte DBCS a zadáte čtvrtý znak pomocí FIND, vyhledávání začne u druhého znaku. FINDB problém řeší.
Všimněte si, že FIND rozlišuje velká a malá písmena, takže můžete hledat konkrétní velká písmena. Pokud chcete použít alternativu bez rozlišování malých a velkých písmen, můžete použít funkci SEARCH, která bere stejné argumenty a vrací stejné hodnoty.
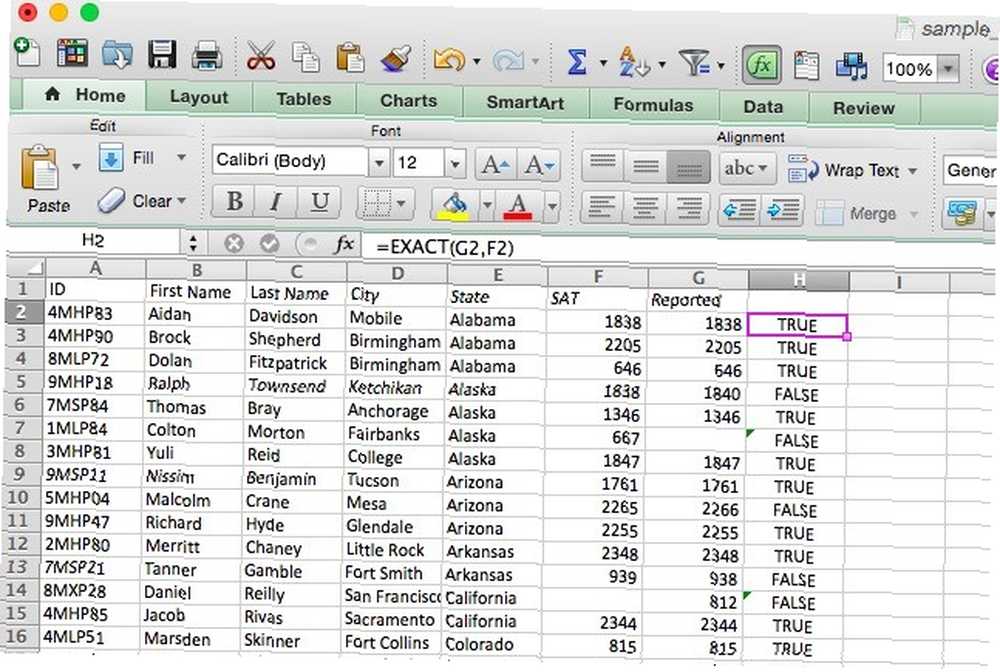
Funkce EXACT
Pokud potřebujete porovnat dvě hodnoty, abyste zjistili, zda jsou stejné, EXACT je funkce, kterou potřebujete. Když dodáte EXACT dvěma řetězcům, vrátí PRAVDA, pokud jsou přesně stejné, a NEPRAVDA, pokud jsou odlišné. Protože EXACT rozlišuje velká a malá písmena, vrátí FALSE, pokud mu dáte řetězce, které čtou “Test” a “test.” Zde je syntaxe EXACT:
= EXACT ([text1], [text2])
Oba argumenty jsou docela sebevysvětlující; jsou to řetězce, které byste chtěli porovnat. V naší tabulce je použijeme k porovnání dvou skóre SAT. Přidal jsem druhý řádek a zavolal jsem to “Hlášeno.” Nyní projdeme tabulku s EXACT a uvidíme, kde se oznámené skóre liší od oficiálního skóre pomocí následující syntaxe:
= EXACT (G2, F2)
Opakování tohoto vzorce pro každý řádek ve sloupci nám dává toto:
Funkce převodu textu
Tyto funkce vezmou hodnoty z jedné buňky a změní je do jiného formátu; například z čísla na řetězec nebo z řetězce na číslo. Existuje několik různých možností, jak postupovat, a co je přesný výsledek.
Funkce TEXT
TEXT převádí numerická data na text a umožňuje vám je formátovat konkrétním způsobem; to by mohlo být užitečné, například pokud plánujete použití dat Excel v dokumentu Word Jak integrovat data Excel do dokumentu Word Jak integrovat data Excel do dokumentu Word Během pracovního týdne je pravděpodobně mnohokrát že kopírujete a vkládáte informace z aplikace Excel do aplikace Word nebo naopak. Takto lidé často vytvářejí písemné zprávy…. Pojďme se podívat na syntaxi a uvidíme, jak ji použít:
= TEXT ([text], [formát])
Argument [format] vám umožňuje zvolit, jak chcete, aby se číslo zobrazovalo v textu. Existuje několik různých operátorů, které můžete použít k formátování textu, ale budeme se držet jednoduchých operátorů (úplné podrobnosti najdete na stránce nápovědy Microsoft Office na TEXTu). TEXT se často používá k převodu peněžních hodnot, takže s tím začneme.
Přidal jsem sloupec s názvem “Výuka” které obsahuje číslo pro každého studenta. Toto číslo zformátujeme na řetězec, který vypadá trochu více, jako bychom byli zvyklí číst peněžní hodnoty. Zde je syntaxe, kterou použijeme:
= TEXT (G2, „$ #, ###“)
Použití tohoto formátovacího řetězce nám poskytne čísla, kterým předchází symbol dolaru, a za stovky míst bude obsahovat čárku. Co se stane, když ji použijeme na tabulku:
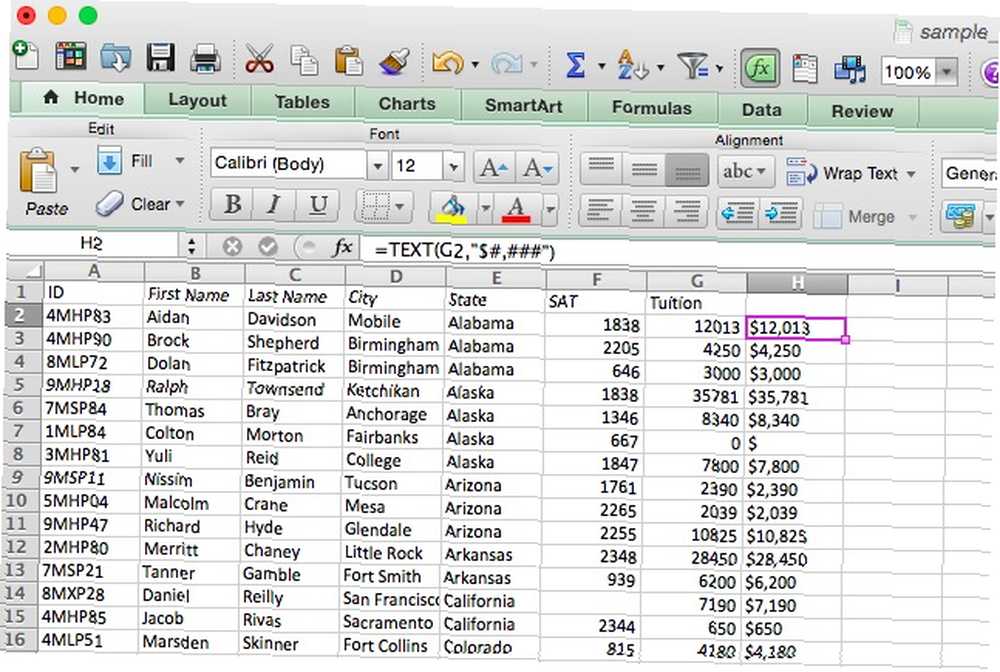
Každé číslo je nyní správně naformátováno. TEXT můžete použít k formátování čísel, hodnot měn, dat, časů a dokonce i k odstranění nepatrných číslic. Podrobnosti o tom, jak dělat všechny tyto věci, naleznete na výše uvedené stránce nápovědy.
Funkce FIXED
Podobně jako TEXT, funkce FIXED bere vstup a formátuje jej jako text; FIXED se však specializuje na převod čísel na text a dává vám několik specifických možností formátování a zaokrouhlení výstupu. Zde je syntax:
= FIXED ([číslo], [desetinná místa], [no_commas])
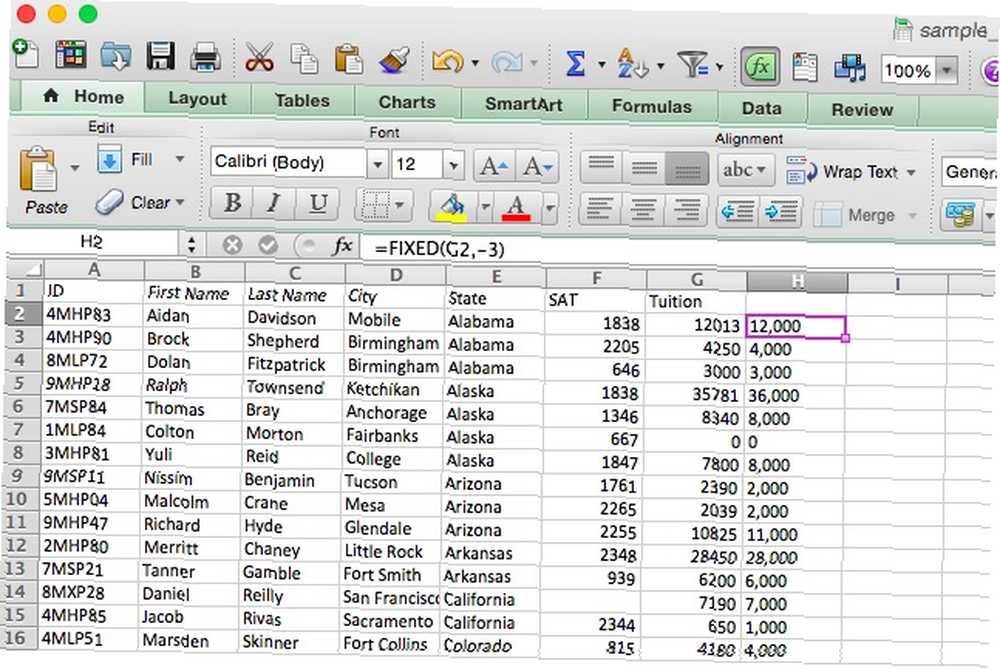
Argument [number] obsahuje odkaz na buňku, kterou chcete převést na text. [desetinná místa] je volitelný argument, který vám umožňuje vybrat počet desetinných míst, která budou zachována při převodu. Pokud je toto 3, dostanete číslo jako 13.482. Pokud použijete pro desetinná čísla záporné číslo, Excel toto číslo zaokrouhlí. Podíváme se na to v níže uvedeném příkladu. [no_commas], pokud je nastavena na PRAVDA, vyloučí z konečné hodnoty čárky.
Použijeme to k zaokrouhlení hodnot výuky, které jsme použili v posledním příkladu, k nejbližším tisícům.
= FIXED (G2, -3)
Při použití na řádek získáme řadu zaoblených hodnot výuky:
Funkce VALUE
Toto je opak funkce TEXT - vezme jakoukoli buňku a změní ji na číslo. To je užitečné zejména v případě, že importujete tabulku nebo zkopírujete a vložíte velké množství dat a bude formátována jako text. Zde je návod, jak to opravit:
= VALUE ([text])
To je všechno. Excel rozpozná přijaté formáty konstantních čísel, časů a dat a převede je na čísla, která pak mohou být použita s numerickými funkcemi a vzorci. Toto je docela jednoduché, takže tento příklad přeskočíme.
Funkce DOLLAR
Podobně jako funkce TEXT, DOLLAR převede hodnotu na text - ale také přidá znak dolaru. Můžete si také vybrat počet desetinných míst, která chcete zahrnout:
= DOLLAR ([text], [desetinná místa])
Pokud ponecháte argument [desetinná místa] prázdný, bude výchozí na 2. Pokud vložíte záporné číslo do argumentu [desetinná místa], bude číslo zaokrouhleno vlevo od desetinné čárky.
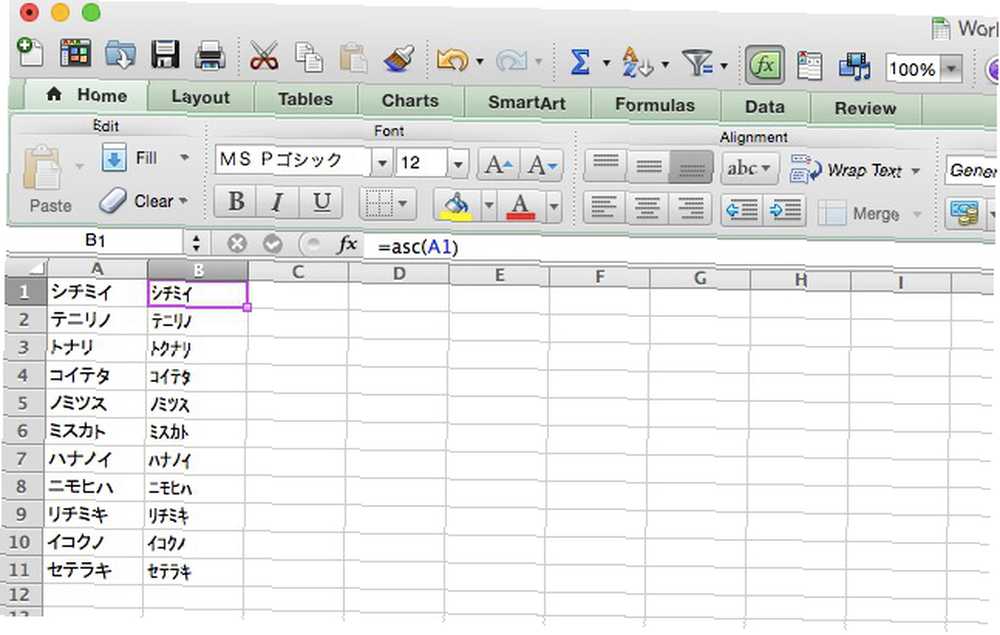
Funkce ASC
Vzpomínáte si na naši diskusi o jednobajtových a dvoubytových postavách? Takto převádíte mezi nimi. Konkrétně tato funkce převádí dvoubajtové znaky plné šířky na poloviční šířku, jednobajtové znaky. Může být použit k uložení určitého místa v tabulce. Zde je syntax:
= ASC ([text])
Docela jednoduché. Stačí spustit funkci ASC u jakéhokoli textu, který chcete převést. Abych to viděl v akci, převedu tuto tabulku, která obsahuje řadu japonských katakana - ty jsou často vykresleny jako znaky plné šířky. Změníme je na poloviční šířku.
Funkce JIS
Samozřejmě, pokud můžete převést jeden způsob, můžete také převést zpět jiným způsobem. JIS převádí z znaků poloviční šířky na znaky plné šířky. Stejně jako ASC je syntaxe velmi jednoduchá:
= JIS ([text])
Myšlenka je docela jednoduchá, takže přejdeme k další části bez příkladu.
Funkce úpravy textu
Jednou z nejužitečnějších věcí, které můžete s textem v Excelu udělat, je programové úpravy. Následující funkce vám pomohou při zadávání textu a dostanete se do přesného formátu, který je pro vás nejužitečnější.
Funkce UPPER, LOWER a PROPER
To vše jsou velmi jednoduché funkce. UPPER vytvoří velká písmena textu, LOWER vytvoří malá písmena a PROPER kapitalizuje první písmeno v každém slově, zatímco zbývající písmena zůstanou malá. Není zde žádný příklad, proto vám dám pouze syntaxi:
= UPPER / LOWER / PROPER ([text])
Vyberte buňku nebo rozsah buněk, ve kterých je váš text, pro argument [text] a jste připraveni jít.
Funkce CLEAN
Import dat do Excelu obvykle jde docela dobře, ale někdy skončíte se znaky, které nechcete. Toto je nejčastější, když jsou v původním dokumentu zvláštní znaky, které Excel nemůže zobrazit. Místo procházení všemi buňkami, které tyto znaky obsahují, můžete použít funkci CLEAN, která vypadá takto:
= CLEAN ([text])
Argument [text] je jednoduše umístění textu, který chcete vyčistit. V příkladu tabulky jsem přidal několik netisknutelných znaků ke jménům ve sloupci A, které je třeba zbavit (v řádku 2 je jeden, který posouvá jméno doprava, a znak chyby v řádku 3) . Použil jsem funkci CLEAN k přenosu textu do sloupce G bez těchto znaků:
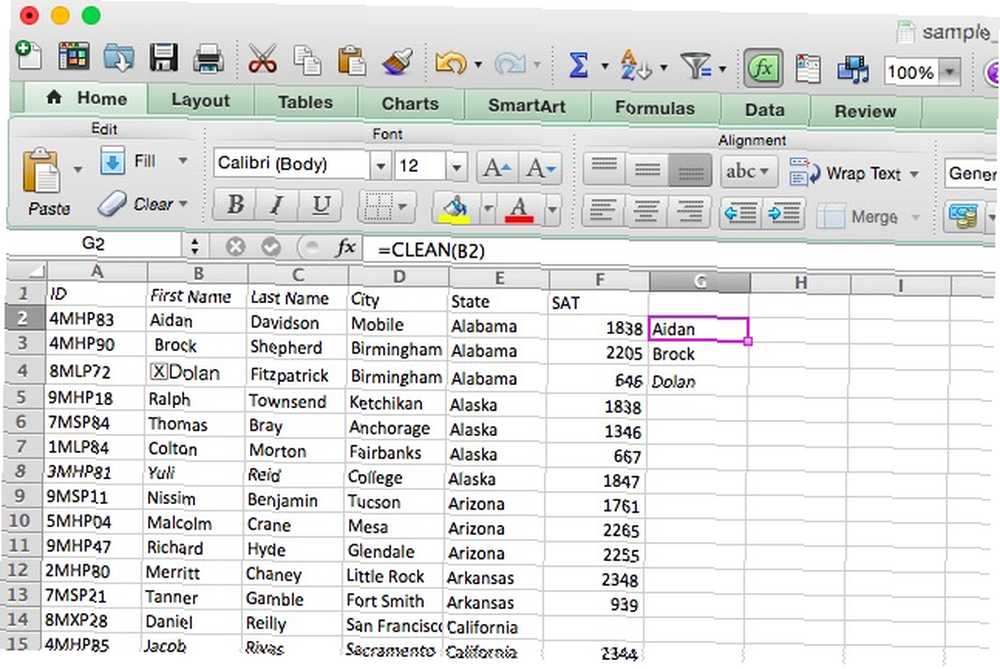
Nyní sloupec G obsahuje jména bez netisknutelných znaků. Tento příkaz není užitečný pouze pro text; často vám může pomoci, pokud čísla zkazí i vaše další vzorce; speciální postavy mohou opravdu propouštět chaos s výpočty. Je důležité, když převádíte z aplikace Word do Excelu Převést Word do Excelu: Převést dokument Word do souboru Excel Převést Word do Excelu: Převést dokument Word do souboru Excel, i když.
Funkce TRIM
Zatímco CLEAN se zbaví netisknutelných znaků, TRIM se zbaví dalších mezer na začátku nebo na konci textového řetězce, který by s nimi mohl skončit, pokud zkopírujete text z Wordu nebo prostého textového dokumentu a skončí s něčím jako ” Datum kontroly ”… Proměnit to v “Datum kontroly,” stačí použít tuto syntaxi:
= TRIM ([text])
Když ji použijete, uvidíte podobné výsledky jako při použití CLEAN.
Funkce nahrazení textu
Někdy budete muset nahradit určité řetězce v textu řetězcem jiných znaků. Použití vzorců Excelu je mnohem rychlejší než hledání a nahrazení Dobytí textových úkolů „Najít a nahradit“ pomocí příkazu wReplace Dobýt textových úkolů „Najít a nahradit“ pomocí příkazu wReplace, zejména pokud pracujete s velmi velkou tabulkou.
Funkce SUBSTITUTE
Pokud pracujete s velkým množstvím textu, někdy budete muset provést některé významné změny, jako je odečtení jednoho řetězce textu za jiný. Možná jste si uvědomili, že v řadě faktur je měsíc nesprávný. Nebo že jste zadali někoho jméno nesprávně. V každém případě je třeba řetězec nahradit. To je to, pro co je SUBSTITUTE. Zde je syntax:
= SUBSTITUTE ([text], [old_text], [new_text], [instance])
Argument [text] obsahuje umístění buněk, které chcete nahradit, a [old_text] a [new_text] jsou docela samovysvětlující. [instance] vám umožňuje určit konkrétní instanci starého textu, který se má nahradit. Pokud tedy chcete nahradit pouze třetí instanci starého textu, zadejte “3” pro tento argument. SUBSTITUTE zkopíruje všechny ostatní hodnoty (viz níže).
Jako příklad opravíme pravopisnou chybu v naší tabulce. Řekněme “Honolulu” byl omylem napsán jako “Honululu.” Zde je syntaxe, kterou použijeme k opravě:
= SUBSTITUTE (D28, "Honululu", "Honolulu")
A tady je to, co se stane, když spustíme tuto funkci:
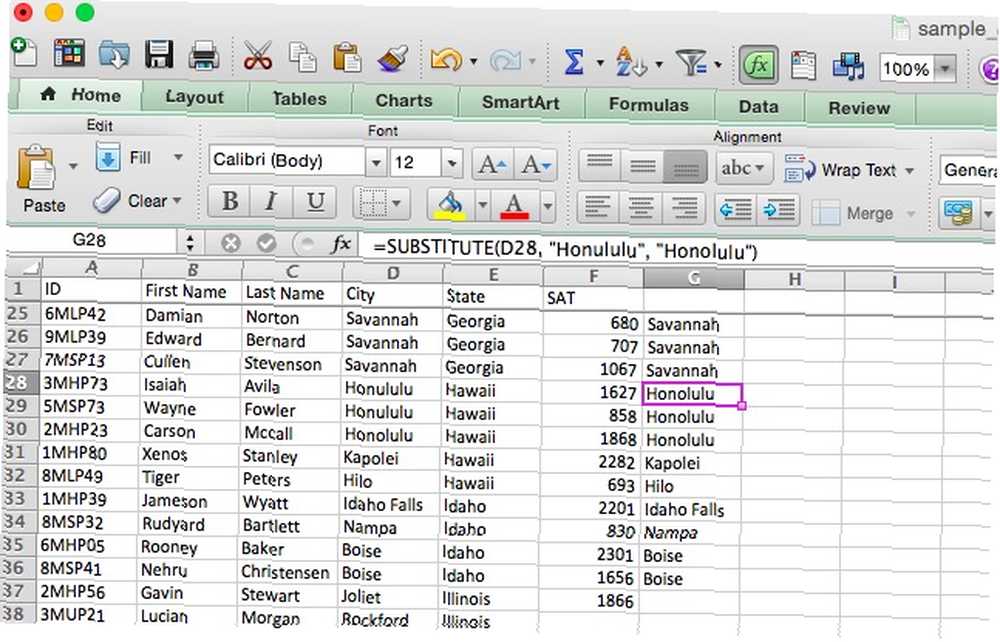
Po přetažení vzorce do okolních buněk uvidíte, že byly zkopírovány všechny buňky ze sloupce D, s výjimkou těch, které obsahovaly pravopisnou chybu “Honululu,” které byly nahrazeny správným hláskováním.
Funkce VÝMĚNA
REPLACE je hodně podobná SUBSTITUTE, ale místo nahrazení určitého řetězce znaků nahradí znaky na konkrétní pozici. Pohled na syntaxi objasní, jak funkce funguje:
= REPLACE ([old_text], [start_num], [num_chars], [new_text])
[old_text] je místo, kde určíte buňky, ve kterých chcete nahradit text. [start_num] je první znak, který chcete nahradit, a [num_chars] je počet znaků, které budou nahrazeny. Uvidíme, jak to funguje za chvilku. [new_text] je samozřejmě nový text, který bude vložen do buněk - může to být také odkaz na buňku, což může být docela užitečné.
Pojďme se podívat na příklad. V naší tabulce mají ID studenta sekvence HP, SP, LP, UP a XP. Chceme se jich zbavit a změnit je na NP, což by trvalo dlouhou dobu pomocí SUBSTITUTE nebo Find and Replace. Zde je syntaxe, kterou použijeme:
= VÝMĚNA (A2, 3, 2, „NP“)
Týká se celého sloupce:
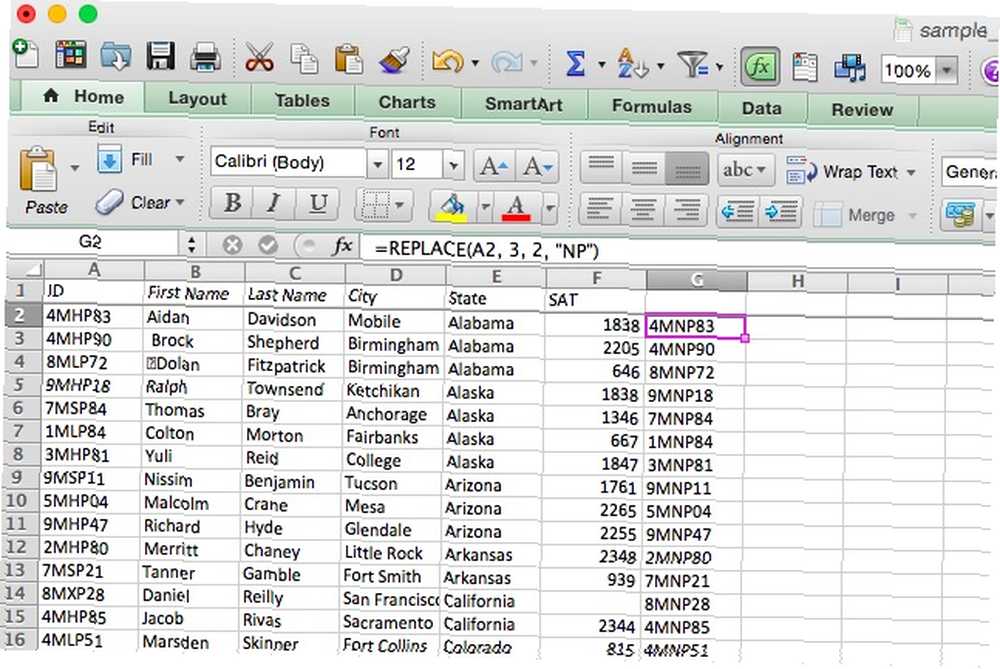
Všechny dvojpísmenné sekvence ze sloupce A byly nahrazeny “NP” ve sloupci G.
Funkce vytváření textu
Kromě provádění změn v řetězcích můžete také dělat věci s menšími částmi těchto řetězců (nebo použít tyto řetězce jako menší k vytvoření větších). Toto jsou některé z nejčastěji používaných textových funkcí v Excelu.
Funkce CONCATENATE
Tohle jsem už několikrát použil sám. Pokud máte dvě buňky, které je třeba sečíst, CONCATENATE je vaše funkce. Zde je syntax:
= CONCATENATE ([text1], [text2], [text3]…)
Propojení je tak užitečné, že argumenty [text] mohou být prostý text “Arizona,” nebo odkazy na buňky jako “A31.” Můžete je dokonce smíchat. To vám může ušetřit spoustu času, když potřebujete kombinovat dva sloupce textu, jako byste potřebovali vytvořit “Celé jméno” sloupec z a “Jméno” a “Příjmení” sloupec. Zde je syntaxe, kterou použijeme:
= KONCATENÁT (A2, "", B2)
Zde si všimněte, že druhým argumentem je prázdné místo (zadané jako uvozovka-mezera-mezera-qoutační značka). Bez tohoto by byla jména zřetězena přímo, bez mezery mezi křestními jmény. Uvidíme, co se stane, když spustíme tento příkaz a použijeme automatické vyplňování ve zbytku sloupce:
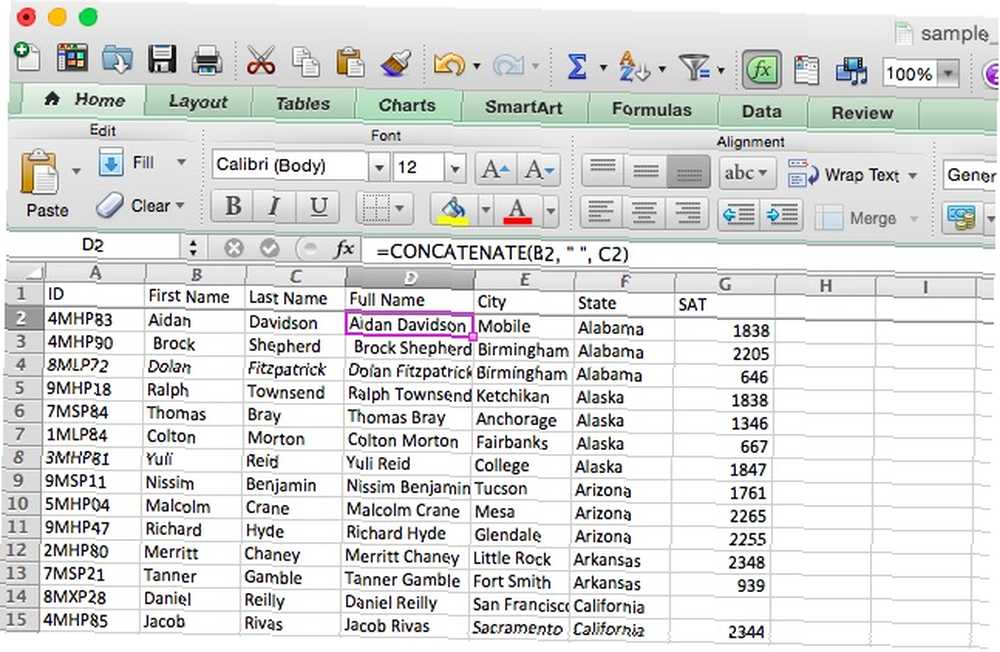
Nyní máme sloupec s celým jménem. Pomocí tohoto příkazu můžete snadno kombinovat předvolby a telefonní čísla, jména a čísla zaměstnanců, města a státy nebo dokonce měny a částky.
Ve většině případů můžete funkci CONCATENATE zkrátit na jediný ampersand. Chcete-li vytvořit výše uvedený vzorec pomocí ampersandu, zadejte toto:
= A2 & "" & B2
Můžete jej také použít ke zkombinování odkazů na buňky a řádků textu, jako je tento:
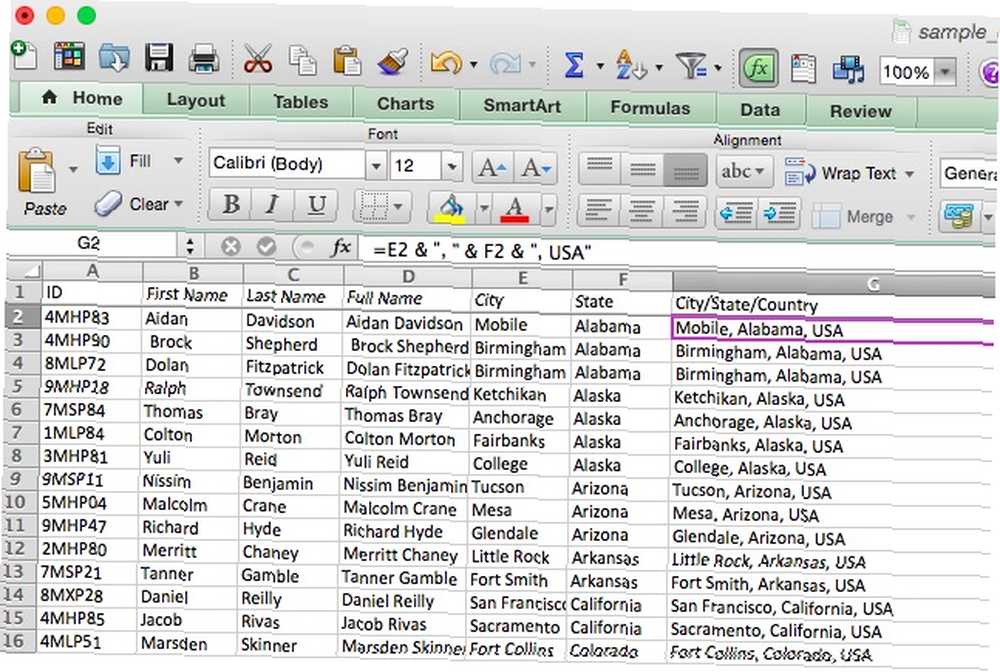
= E2 & "," & F2 & ", USA"
Toto vezme buňky s názvy měst a států a kombinuje je “USA” získat úplnou adresu, jak je vidět níže.
Funkce VLEVO a VPRAVO
Často chcete pracovat pouze s prvním (nebo posledním) několika znaky textového řetězce. VLEVO a VPRAVO vám to umožní návratem pouze určitého počtu znaků počínaje znakem zleva nebo úplně vpravo v řetězci. Zde je syntax:
= LEFT / RIGHT ([text], [num_chars])
[text] je samozřejmě původní text a [num_chars] je počet znaků, které chcete vrátit. Pojďme se podívat na příklad, kdy to budete chtít udělat. Řekněme, že jste naimportovali několik adres a každá obsahuje státní zkratku i zemi. Pomocí LEFT můžeme získat pouze zkratky, pomocí této syntaxe:
= VLEVO (E2, 2)
Zde vypadá, jak to vypadá v naší tabulce:
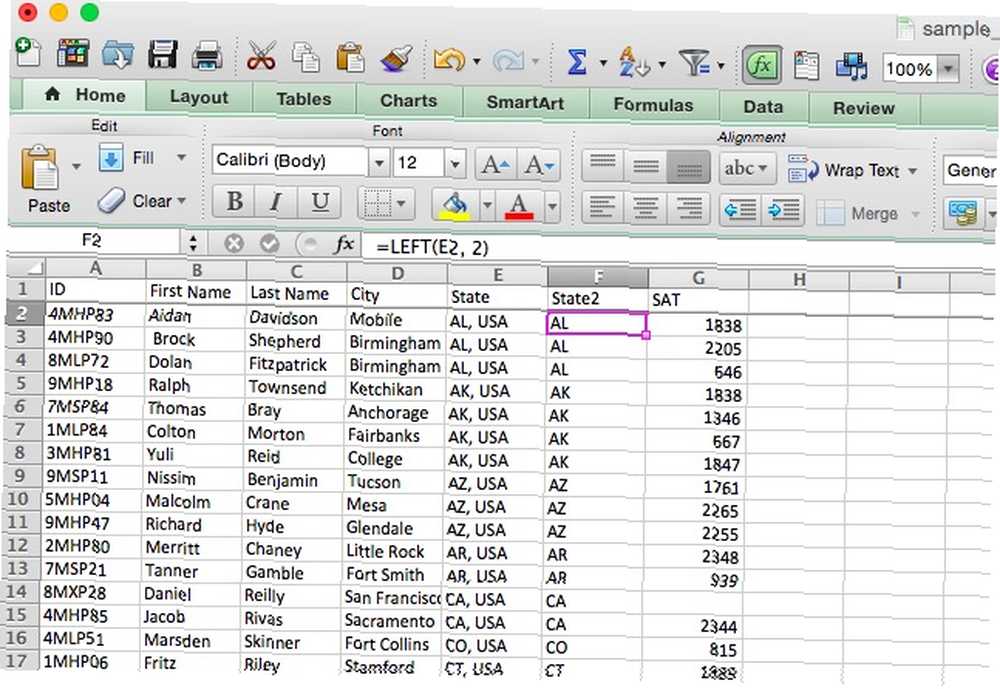
Pokud by zkratka přišla po stavu, použili bychom PRAVDĚ stejným způsobem.
Funkce MID
MID je hodně podobné LEVÉ a PRAVÉ, ale umožňuje vytáhnout postavy ze středu řetězce, počínaje určenou pozicí. Pojďme se podívat na syntaxi a uvidíme přesně, jak to funguje:
= MID ([text], [start_num], [num_chars])
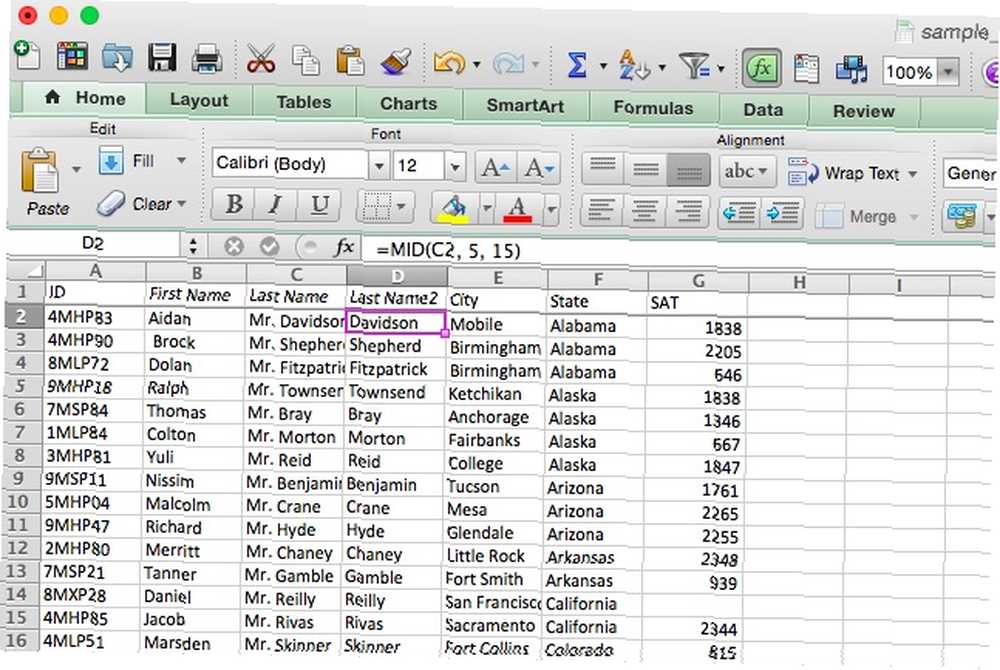
[start_num] je první znak, který bude vrácen. To znamená, že pokud chcete, aby byl první znak v řetězci zahrnut do výsledku funkce, bude to “1.” [num_chars] je počet znaků za počátečním znakem, který bude vrácen. Uděláme s tím trochu čištění textu. V tabulce s příklady máme nyní k příjmením přidané tituly, ale rádi bychom je odstranili, takže příjmení “Pan Martin” bude vrácena jako “Martin.” Zde je syntax:
= MID (A2, 5, 15)
Budeme používat “5” jako počáteční znak, protože první písmeno jména osoby je pátý znak (“pan. ” zabírá čtyři mezery). Funkce vrátí dalších 15 písmen, což by mělo stačit, aby nedošlo k oříznutí poslední části jména někoho. Zde je výsledek v Excelu:
Podle mých zkušeností považuji MID za nejužitečnější, když jej kombinujete s jinými funkcemi. Řekněme, že v této tabulce byly zahrnuty nejen ženy, ale i ženy, které by mohly mít “slečna.” nebo “paní.” za jejich tituly. Co bychom potom udělali? MID můžete kombinovat s IF a získat křestní jméno bez ohledu na název:
= IF (LEFT (A2, 3) = "Mrs", MID (A2, 6, 16), MID (A2, 5, 15)
Nechám vás přijít na to, jak přesně tento vzorec funguje svou magií (možná budete muset zkontrolovat booleovské operátory Excelu Mini Excel Tutorial: Použijte Boolean Logic pro zpracování komplexních dat Mini Excel Tutorial: Použijte Boolean Logic pro zpracování komplexních dat Logické operátory IF, NOT , AND a OR vám mohou pomoci přejít od nováčků k výkonnému uživateli. Vysvětlujeme základy každé funkce a ukážeme, jak je můžete použít pro dosažení maximálních výsledků.).
Funkce REPT
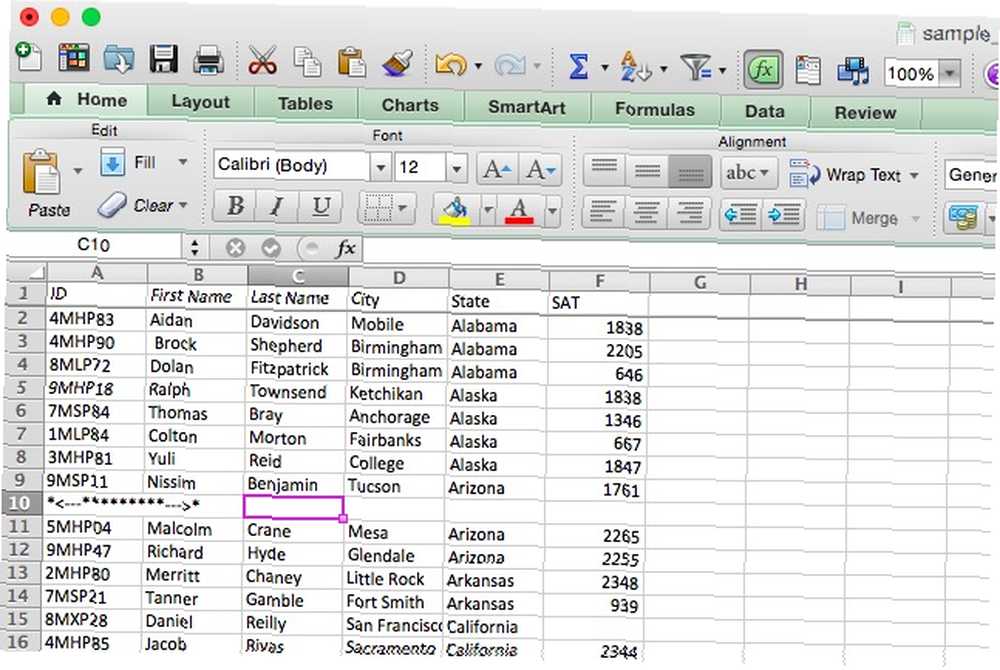
Pokud potřebujete vzít řetězec a opakovat to několikrát, a raději byste jej nenapsali znovu a znovu, může vám pomoci REPT. Zadejte řetězec REPT (“abc”) a několikrát (3), kolikrát chcete, aby se to opakovalo, a Excel vám dá přesně to, co jste požadovali (“abcabcabc”). Zde je velmi snadná syntaxe:
= REPT ([text], [číslo])
[text] je samozřejmě základní řetězec; [number] je počet opakování. I když jsem ještě nezačal dobře využívat tuto funkci, jsem si jistý, že někdo tam mohl něco použít. Použijeme příklad, který, i když to není úplně užitečné, vám může ukázat potenciál této funkce. Spojíme REPT s “&” vytvořit něco nového. Zde je syntax:
= "**"
Výsledek je uveden níže:
Příklad ze skutečného světa
Abych vám dal představu o tom, jak byste mohli použít textovou funkci v reálném světě, uvedu příklad, kde jsem ve své vlastní práci kombinoval MID s několika podmínkami. Pro můj postgraduální psychologický titul jsem provedl studii, ve které účastníci museli kliknout na jedno ze dvou tlačítek a byly zaznamenány souřadnice tohoto kliknutí. Tlačítko na levé straně obrazovky bylo označeno A a jedno na pravé straně bylo označeno B. Každá zkouška měla správnou odpověď a každý účastník provedl 100 pokusů.
K analýze těchto údajů jsem potřeboval zjistit, kolik pokusů měl každý účastník pravdu. Tady vypadá tabulka výsledků po trochu vyčištění:
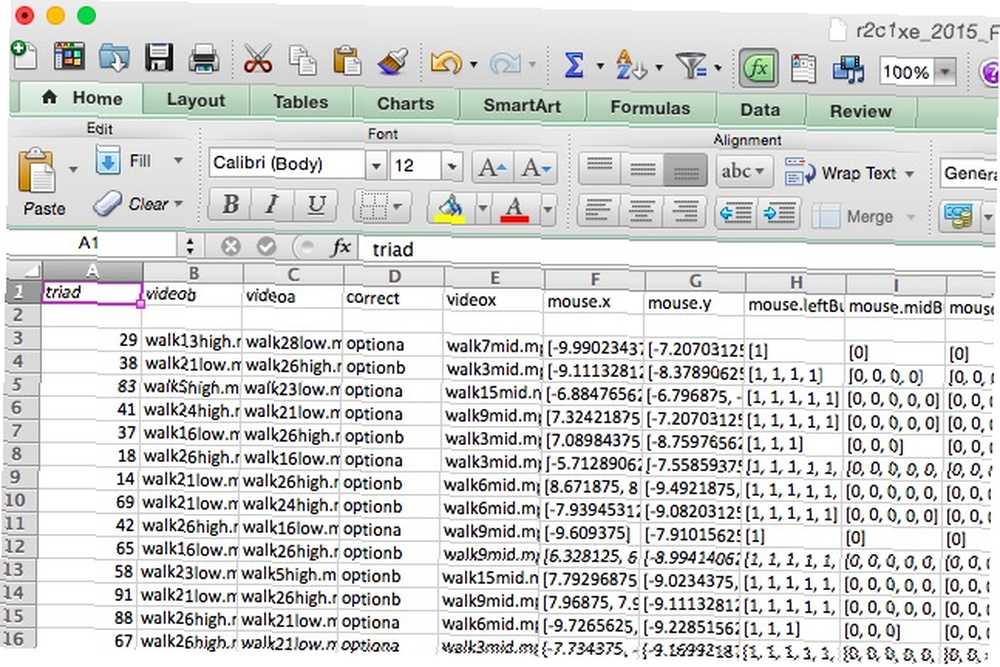
Správná odpověď pro každý pokus je uvedena ve sloupci D a souřadnice kliknutí jsou uvedeny ve sloupcích F a G (jsou formátovány jako text, což je složité). Když jsem začal, jednoduše jsem prošel a provedl analýzu ručně; pokud se uvedl sloupec D “opce” a hodnota ve sloupci F byla záporná, zadal bych 0 (pro “špatně”). Pokud by to bylo pozitivní, zadal bych 1. Opak byl pravdou, kdyby se sloupec D četl “optionb.”
Po trošce šťourání jsem přišel na způsob, jak použít funkci MID, abych pro mě udělal práci. Zde je to, co jsem použil:
= IF (D3 = "optiona", IF (MID (F3,2,1) = "-", 1,0), IF (MID (F3,2,1) = "-", 0,1))
Pojďme to rozebrat. Počínaje prvním příkazem IF máme následující: “pokud buňka D3 říká 'optiona', pak [první podmínka]; pokud ne, pak [druhá podmínka].” První podmínka říká toto: “je-li druhý znak buňky F3 spojovník, vraťte true; pokud ne, vraťte nepravdivé.” Třetí říká “je-li druhý znak buňky F3 spojovník, vraťte false; pokud ne, vraťte true.”
Může to chvíli trvat, než si to obejdete, ale mělo by to být jasné. Stručně řečeno, tento vzorec zkontroluje, zda D3 říká “opce”; pokud ano, a druhý znak F3 je spojovník, funkce se vrací “skutečný.” Pokud D3 obsahuje “opce” a druhá postava F3 není spojovník, vrací se “Nepravdivé.” Pokud D3 ne obsahovat “opce” a druhý znak F3 je spojovník, vrací se “Nepravdivé.” Pokud D3 neříká “opce” a druhá postava F2 není spojovník, vrací se “skutečný.”
Při spuštění vzorce vypadá tabulka takto:
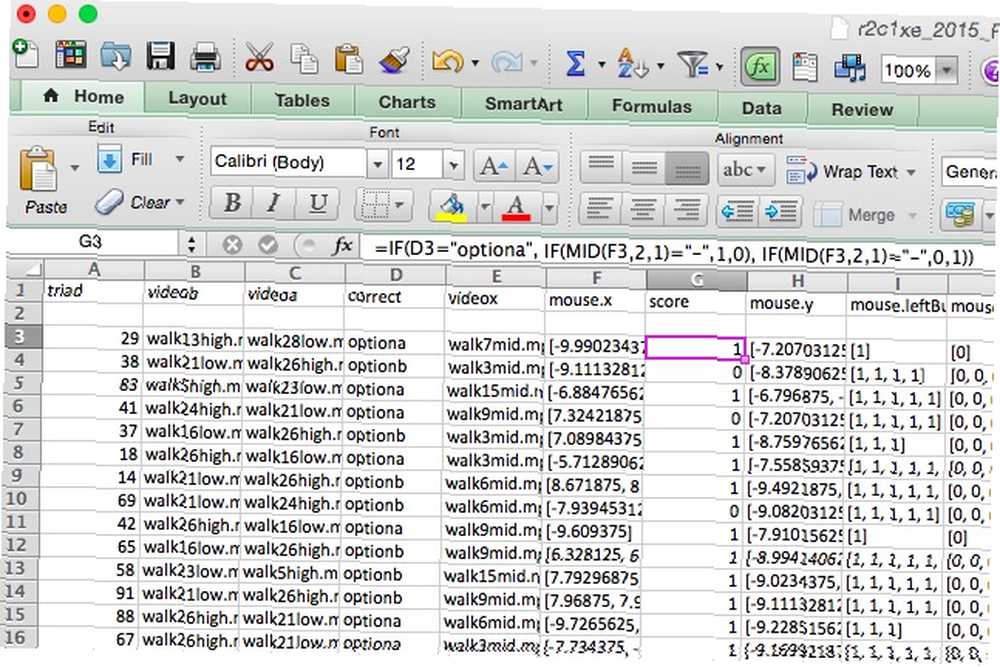
Nyní, “skóre” sloupec obsahuje 1 pro každý pokus, na který účastník odpověděl správně, a 0 pro každý pokus, na který odpověděl nesprávně. Odtud je snadné sčítat hodnoty a zjistit, kolik mají pravdu.
Doufám, že tento příklad vám dá představu o tom, jak můžete kreativně používat textové funkce, když pracujete s různými typy dat. Excel je výkon téměř neomezený 3 Crazy Excel vzorce, které dělají úžasné věci 3 Crazy Excel vzorce, které dělají úžasné věci Excel vzorce mají výkonný nástroj v podmíněném formátování. Tento článek popisuje tři způsoby, jak zvýšit produktivitu s MS Excel. , a pokud si uděláte čas, abyste přišli s vzorcem, který vám udělá práci, můžete ušetřit spoustu času a úsilí!
Excel Text Mastery
Excel je powerhouse, pokud jde o práci s čísly, ale má také překvapivé množství užitečných textových funkcí. Jak jsme viděli, můžete analyzovat, převádět, nahrazovat a upravovat text a kombinovat tyto funkce s ostatními, provádět složité výpočty a transformace.
Z odesílání e-mailů Jak posílat e-maily z tabulky Excelu pomocí skriptů VBA Jak posílat e-maily z tabulky Excelu pomocí skriptů VBA Naše kódová šablona vám pomůže nastavit automatické e-maily z aplikace Excel pomocí skriptů CDO (Collaboration Data Objects) a VBA. dělat své daně Dělat své daně? 5 vzorců aplikace Excel, které musíte znát při provádění daní? 5 vzorců Excelu, které musíte vědět Je to dva dny před splatností daní a nechcete platit další poplatek za pozdní podání. Toto je čas využít sílu Excelu, aby vše bylo v pořádku. , Excel vám pomůže spravovat celý život Jak používat Microsoft Excel pro správu svého života Jak používat Microsoft Excel pro správu vašeho života Není tajemstvím, že jsem naprosto fanoušek Excelu. Hodně z toho plyne ze skutečnosti, že mě baví psaní kódu VBA a Excel v kombinaci se skripty VBA otevírá celý svět možností…. A naučit se používat tyto textové funkce vás přiblíží o krok blíže k tomu, abyste byli mistrem Excel.
Dejte nám vědět, jak jste použili textové operace v Excelu! Jaká nejsložitější transformace jste provedli?